In This Article
- 01 Why I wrote this now
- 02 Where are you right now
- 03 What does 'agentic' actually mean
- 04 Stop thinking in tools. Start thinking in systems.
- 05 The knowledge base is the real commercial asset
- 06 The Signals Layer
- 07 Strategy is the missing layer in most AI deployments
- 08 Execution - the use case library
- 09 Emma (Our Marketing Agent)
- 10 Memory and observability - the compounding loop
- 11 The tooling landscape
- 12 What this won’t fix
- 13 Who owns what as you scale
- 14 Trust, security, and compliance
- 15 Build for now and the future
- 16 How to actually start
- 17 Why this matters right now
- 18 APPENDICES
01 Why I wrote this now
I wrote this article because I'm tired of AI posts that tell you what's possible without telling you how to build it.
You know the kind of post I mean. It opens with a robot image, spends 2,000 words re-explaining large language models, and ends with a vague conclusion about how companies should “embrace innovation.” It sounds smart, but it does not help an operator build anything real.
That’s not what this is.
Everything here comes from building. At Succession, we've been on the forefront of using AI in go-to-market. We use AI every single day and for context have used over 10 billion tokens in the last few months. We've built internal tools to make our jobs faster and free external tools we release to the community. But where the real shift happened is when we started building agents that do real work inside our organization.
Emma is our CMO agent. She runs our marketing operations. She handles SEO strategy, content pipeline, CRO, campaign execution, analytics. She doesn't sleep. She doesn't forget context between Monday and Thursday. Neo is our support agent. He handles troubleshooting, bug fixes, and general technical support for the team, work that used to bottleneck through me. We're deploying more agents across the business, each one scoped to a specific function with access to the systems and context it needs to operate. What you're reading is what we've learned building them.
I should be clear about something. I am not an engineer. I don't write production code. I'm a commercial operator who got curious about what these tools could do, started building, and learned by running things and breaking them. Everything in this article was built by someone with domain expertise and persistence, not a computer science degree. If you're reading this thinking "this sounds technical and I'm not technical," you're exactly who I wrote it for.
Succession has worked with over 100 life science companies on commercial execution. Everything from instrument makers, reagent companies, CROs, CDMOs, diagnostics, software, and lab automation businesses. We've written the outbound messaging, built the targeting, and run the campaigns. That body of work, thousands of campaigns, millions of messages, tens of thousands of prospect replies, is the dataset behind everything in this article. When I describe what works in cold outreach to a VP of Quality at a mid-size CDMO, it's because we've sent that message and measured the result. When I describe how a knowledge base should be structured, it's because we've built and rebuilt ours across dozens of client engagements. This is not a framework invented in a strategy offsite. It's pattern recognition from doing the work.
The core claim in this article is: AI is not just making commercial teams faster. It is restructuring how revenue work gets done.
Sales and marketing are merging into a single AI-managed revenue function. Not philosophically, but structurally. The old structure, where marketing generates leads, sales follows up, RevOps cleans up the mess, and nobody shares a common system of memory, is starting to break down. What replaces it is a more continuous operating model. One where knowledge is centralized, signals are monitored constantly, actions are triggered automatically, performance is logged, and the system improves with every cycle.
Companies that see this clearly and build toward it now will have a structural advantage that compounds. The unit economics of their commercial function will improve every quarter as the system learns. The companies that wait will still be debating whether to invest in AI when their competitors have already built a two-year head start into their cost structure.
This article is for commercial leaders and founders at life science companies. Instrument makers. Reagent companies. CROs, CDMOs, software vendors, lab automation companies. If you sell to scientists, clinicians, or biopharma operators, this is for you.
Here is what we are going to cover:
- Where most teams actually are today
- What “agentic” really means and what it does not
- The architecture behind an AI-managed revenue function
- Why knowledge bases and signals matter more than most teams realize
- What useful execution workflows look like in practice
- What this will not fix
- How to start without overcomplicating it
My goal is not to help you sound informed about AI.
My goal is to help you build.
By the end of this, you’ll have everything you need to get started. The real question is, will you do anything about it? Or will you continue to believe AI is hype and it’s not ready?
Let's start with where you actually are.
02 Where are you right now
I tend to come across a couple of specific archetypes of AI users. There are those who used the free version of ChatGPT a year ago and said it’s overhyped and not useful and they haven’t touched it since. There are those who use it daily as a chat agent but are still on the free or low-tier plans that don’t have any reasoning or context on your company which means you have to be a master prompt engineer to get any meaningful output.
There are others who are deeply excited by the technology but get overwhelmed by how much is going on so they get decision paralysis and do nothing. So they know what’s possible and can talk about it with people, but they’ve never actually put any of that knowledge to work. They see a silly output from AI that goes viral on IG and just assume this is what AI isn’t ready for prime time.
Then there are those who are AI-pilled. They’re on X (Twitter) every day, reading what’s new and what’s possible and immediately implementing what they read. They’re constantly tinkering and experimenting and are genuinely curious people who want to push the boundaries of what’s possible.
Before you can build toward anything, you need an honest read on your starting point. Most commercial leaders I talk to overestimate their current state by one or two levels. That gap costs real money, because they're trying to implement Level D solutions on top of Level B infrastructure and wondering why it's not working.
Here are the six levels. Be honest about which one describes your operation today.
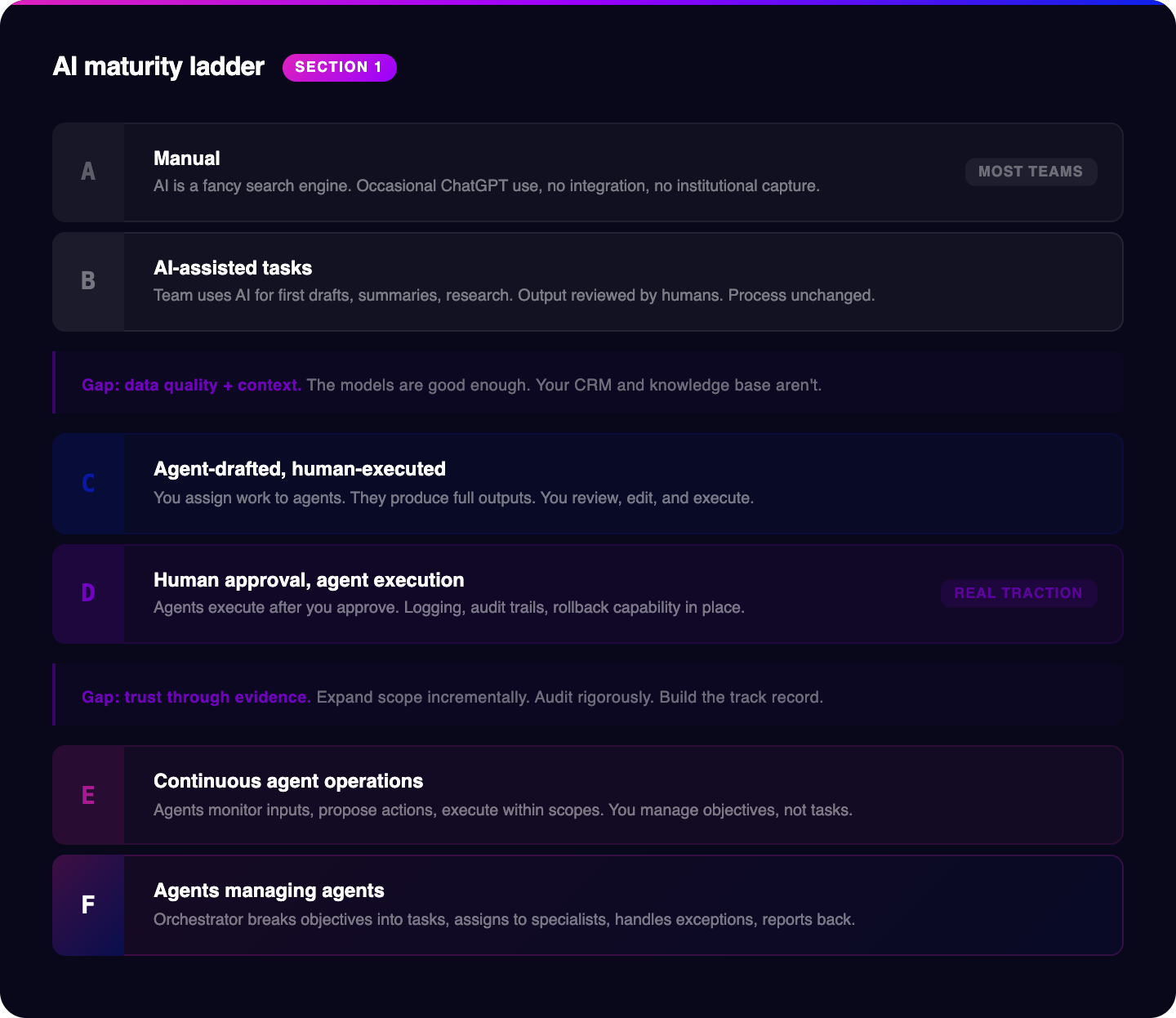
Level A: Manual
AI is a fancy search engine. Someone on your team uses ChatGPT occasionally to draft an email or summarize a document. There's no systematic use, no integration with your actual stack, no shared prompts, no institutional knowledge being captured. If the person who uses it most leaves, nothing changes for the organization. Most commercial orgs in life sciences were here 18 months ago. A surprising number are still here.
What this feels like:
everyone works in isolation and you still have to do all the work.
Biggest weakness:
nothing compounds.
Next move:
document your commercial fundamentals and pick one recurring task to improve.
Level B: AI-assisted tasks
This is where most people reading this article are sitting right now. Your team uses AI tools to accelerate discrete tasks: first drafts of emails and content, research summaries, call note cleanup, competitive brief generation. The output is reviewed and executed by a human. AI is making individual contributors faster, but it's not changing how your commercial system works. The process is the same. The person is just slightly faster. This is better than nothing. It's not the structural shift.
What this feels like:
people work a bit faster.
Biggest weakness:
the operating model has not changed.
Next move:
connect one real data source and deploy one repeatable workflow.
Level C: Agent-drafted, human-executed
You've started assigning work to agents rather than using them as autocomplete. You write a brief, the agent produces a full outreach sequence, a content plan, a research report. You review it, edit it, and execute it yourself. The agent is a contractor, not an employee. You still hold every decision and execute every action. The quality ceiling here depends almost entirely on how good your prompting and your knowledge base are. Most people who think they're at Level C are actually at Level B with better prompts.
What this feels like:
the agent behaves like a contractor.
Biggest weakness:
every action still waits on a human.
Next move:
move one low-risk workflow from draft-only to approved execution.
Level D: Human approval, agent execution
This is where real traction starts. The agent doesn't just draft work, it executes work after you approve it. The agent sends the email. The agent updates the CRM record. The agent triggers the next workflow step. Critically, you have logging, audit trails, and rollback capability. You can see exactly what the agent did and undo it if it was wrong. This requires actual infrastructure: integrations, permissions models, observability tooling. Most life science commercial teams aren't here yet. The ones who are feel the difference immediately.
What this feels like:
real leverage where AI feels like an employee.
Biggest weakness:
most teams discover their data and governance gaps at this stage.
Next move:
add observability, permissions, and tighter workflow design.
Level E: Continuous agent operations
Agents aren't waiting for you to assign tasks. They're monitoring defined inputs, proposing actions within defined parameters, and executing within defined scopes. You review outcomes. An agent is watching your target account list for hiring signals and proactively doing outreach. Another is monitoring deal velocity and flagging accounts that have gone quiet. Another is running A/B tests on your outbound sequences and reporting weekly on what's working. Another is monitoring SEO keywords and ranking, and drafting new articles. Another is monitoring web traffic and bounce rates to optimize your landing pages. You've shifted from managing tasks to managing objectives.
What this feels like:
you manage outcomes more than tasks.
Biggest weakness:
trust and governance become central.
Next move:
expand scope carefully and build stronger feedback loops.
Level F: Agents managing agents
You set the objectives and the guardrails. The rest is a hierarchy of autonomous systems. An orchestrator agent breaks down objectives into tasks, assigns them to specialist agents, monitors execution, handles exceptions, and reports back. You're reviewing performance dashboards and adjusting strategy, not individual actions. This is not science fiction. A small number of commercial operations are running at this level today. They are building a compounding advantage that will be very difficult to close in two years.
What this feels like:
a true operating system.
Biggest weakness:
poor governance or weak architecture becomes very expensive.
Next move:
refine orchestration, approvals, and measurement.
Most life science commercial organizations are at Level A or B. A small number are at Level C. Very few are at Level D or beyond.
The gap between B and D is not a technology problem. The models are good enough. The tooling exists. The gap is data quality, context, and governance. Agents need clean, structured, accessible data to act on. They need defined permissions to act within. They need logging infrastructure so you can see and trust what they're doing. If your CRM is a mess and your content is scattered across six platforms, your agents will be confused and your outputs will reflect that.
The gap between D and F is a trust problem. Not trust in the technology philosophically, trust built through demonstrated reliability in your specific environment. The path from D to F is cumulative evidence that the system works, edge cases are handled, and decision quality is consistent enough to warrant broader delegation. You build that evidence intentionally, by expanding scope incrementally and auditing rigorously.
What to do now
- Figure out honestly where you are. Then ask one more question: what is the next level that would create real value for us in the next 90 days?
- That is the only level you need to care about right now.
Take the quick assessment below (it’s only a few questions and you’ll know exactly where you stand)
03 What does 'agentic' actually mean
The word "agentic" is getting used to describe everything from a GPT wrapper to a fully autonomous pipeline. That range of meaning is a problem, because it means people are comparing completely different things and drawing completely wrong conclusions about what's possible.
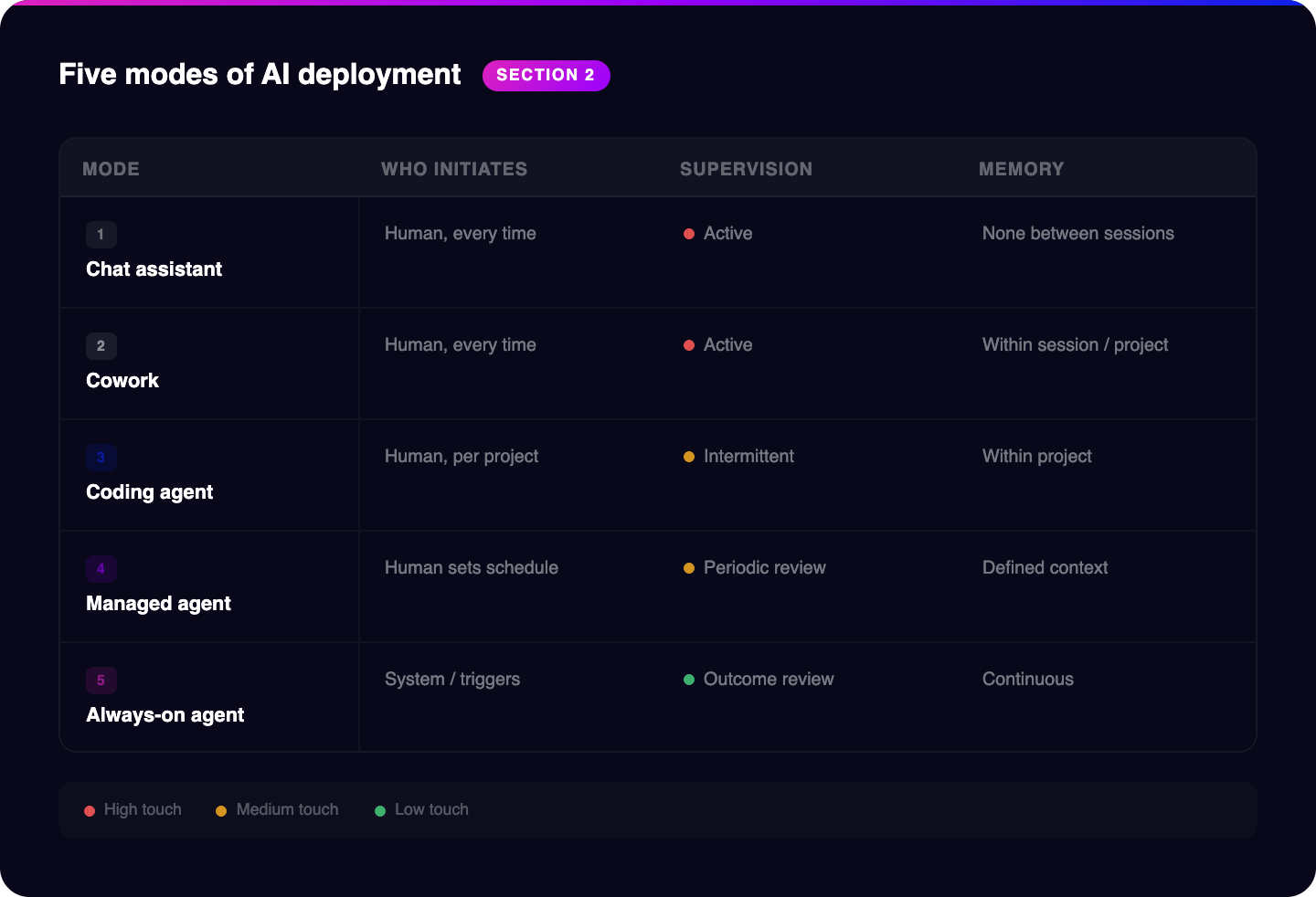
There are five distinct modes of AI deployment. They're not a spectrum where more is always better. They're different tools with different use cases and different infrastructure requirements. Let me walk through each of them.
The first mode is the chat assistant, and it's what most people mean when they say they're "using AI." A single session, you do everything, the model helps you think and draft. It's genuinely useful for one-offs: summarizing a document, drafting an email, researching a company before a call. The ceiling is that it's you-dependent. You have to start it, direct it, execute the output. It doesn't learn from session to session. It has no memory of what you worked on last Tuesday. It's a very good tool. It is not a system.
The second mode is what I'd call cowork. This is multi-step knowledge work in a shared workspace, closer to a persistent working environment than a chat window. Tools like Notion AI or a configured Claude Project start to look like this. The agent can hold context across a longer task, pull from a knowledge base you've built, and work through a problem in multiple steps. The key constraint: you still have to start each task. It requires you to show up, frame the work, and check the output. Cowork becomes genuinely useful when you've invested in the knowledge base and the integrations. Without them, it's a nicer chat interface.
The third mode is coding agents. Claude Code, Codex, and their equivalents. This is worth calling out separately because it changes something specific and important for commercial teams: the cost of building internal tools collapses. "We should build a tool that automatically pulls our CRM data and formats it for competitive reporting" used to be a two-week engineering project. With a coding agent, it's a day of iteration. This matters because it means commercial operators can build the integrations and automations they actually need without waiting in an engineering queue.
The fourth mode is managed agents. Long-running, asynchronous work without constant supervision. You define the task, set the parameters, point the agent at the right data sources, and come back to the output. Overnight account enrichment. Continuous monitoring of a signal feed. Scheduled content generation. The agent runs without you watching. This is where the productivity math starts to change fundamentally.
The fifth mode is always-on agents. Persistent, proactive, continuous memory. The agent isn't waiting for a task. It's watching, processing, updating, and acting within its defined scope all the time. Emma, our marketing agent at Succession, runs in this mode. She's monitoring signals, generating content, testing and adjusting outreach, and maintaining a live picture of our target account landscape while I'm doing other things.
Here's the one distinction that separates everything else: tools wait to be used. Agents do work while you sleep.
That's the structural change. Tools amplify human effort. Agents replace effort. The minute an agent can decide what to do next, execute it, observe the result, and adjust without waiting for a human prompt, you've crossed into a different kind of commercial operation.
| Mode | Who initiates | Supervision needed | Memory | Example use case |
|---|---|---|---|---|
| Chat / Assistant | Human, every time | Active | None between sessions | Drafting a one-off email |
| Cowork | Human, every time | Active | Within session / project | Building a content brief |
| Coding Agent | Human, per project | Intermittent | Within project | Building a CRM integration |
| Managed Agent | Human, sets schedule | Periodic review | Defined context | Overnight account enrichment |
| Always-on Agent | System / triggers | Outcome review | Continuous | Emma, revenue monitoring |
From my observations, the life sciences as a sector generally lags the broader commercial AI adoption curve by 12 to 24 months. Partly regulatory caution. Partly the complexity of the buyer. Partly a culture that are scientist first and commercial second. That lag, right now, is an asymmetric first-mover opportunity. The companies that get to Level D and E infrastructure in the next 12 months are going to look very different from their competitors by the time those competitors start trying to catch up.
What to do now
- List the AI workflows you use today and label each one: chat assistant, cowork, coding agent, managed agent, or always-on agent.
- Pick one workflow that should move from chat to cowork or from cowork to managed-agent territory.
- Pick the one where the stakes are low but the effort is high
04 Stop thinking in tools. Start thinking in systems.
Stop thinking about AI as a collection of tools. Start thinking about it as a layered operating system for your commercial function.
Every serious agentic revenue operation I've seen, across our own work and our clients', resolves into the same structural layers. Each layer has a specific job. Each layer depends on the one below it. Skip a layer and you end up with something that demos impressively and breaks under real-world pressure. Imagine ripping a page out of your SOP in the lab and expecting it to still work. The architecture isn't optional once you're past Level C. It's the difference between a system and a collection of expensive experiments.
There are eight layers. Here's how they work and where they break.
Layer 1: Data and Tools
This is your foundation, and it is almost certainly your biggest problem. CRM data, marketing automation records, analytics, call recordings, product usage data, documents, ad performance, campaign results. IQVIA reported in 2025 that 36% of life science organizations say their data is insufficient to support AI initiatives. I believe that number is conservative, because most organizations don't know what "sufficient" actually means until they try to do something specific with the data.
Agents amplify what's in front of them. If your CRM has incomplete contact records, inconsistent stage definitions, and activity logs that reps fill out reluctantly with minimum required information, your agents will work with exactly that. Fix the data before you build the agents.
AI can also help fix these data gaps and integrations for you. But this has to be where you start. Unsexy, but a messy foundation doesn't get cleaner when you put AI on top of it. It gets messier, faster.
What breaks without it:
unreliable output, shallow recommendations, incorrect actions.
What good looks like:
a small set of trusted systems with usable, current, accessible data.
Layer 2: Connectivity (MCP)
Model Context Protocol is the USB-C of the AI stack. Before MCP, connecting an AI agent to a new data source or external system meant writing a custom integration. Then writing another one for the next system. And another. The N-by-M problem: N agents, M systems, N times M custom connectors, each one a maintenance burden. MCP standardizes how agents connect to external systems, so a connector built once works across any compliant model.
Companies that invest in MCP-compatible connectivity today are building composable, durable stacks. Every new agent you deploy can use the connectors that already exist. Companies that skip this layer have a tangle of brittle custom integrations that breaks every time a vendor pushes an API update or you switch models. It's technical debt that compounds. Many of the tools your using probably already have MCPs built that you can leverage immediately.
What breaks without it:
manual handoffs, duplicated effort, fragile workflows.
What good looks like:
agents can reliably retrieve context and take defined actions in the systems that matter.
Layer 3: Knowledge Base
Not the Google Drive folder or SharePoint where content and decks go to die. A properly built knowledge base is a living, queryable, versioned operating system of organizational truth. It's the single most important input to every agent in your stack.
Without a good knowledge base, your agents are generic. They'll produce outputs that sound like a well-informed outsider with no specific knowledge of your business, your customers, or your competitive position. With a properly built knowledge base, your agents are grounded in your specific reality. They know your positioning, your personas, your proof points, your objections, your competitive differentiation. The quality ceiling of every agent in your stack is set by the quality of your knowledge base. I'll go deep on this in Section 4.
What breaks without it:
generic output, vague messaging, inconsistent reasoning.
What good looks like:
a living, structured, queryable body of commercial truth.
Layer 4: Signals and Intelligence
Raw data doesn't drive commercial decisions. Signals do. Layer 4 is the translation layer that takes raw inputs from Layer 1, normalizes them, scores them, and surfaces intelligence that agents and humans can act on. Intent data, deal velocity changes, engagement decay patterns, objection frequencies, stage readiness scores, competitive mention spikes. This layer is what makes your commercial operation proactive rather than reactive.
Without Layer 4, you're running on lagging indicators. You find out a deal is at risk when the prospect stops responding. You find out a competitor is gaining ground when you lose a deal. Layer 4 tells you before that happens. Section 5 covers the full signal universe, because this layer is where life science commercial teams have the most untapped data and the least built infrastructure.
What breaks without it:
you always discover important changes too late.
What good looks like:
the system detects changes that matter and routes them into planning or action.
Layer 5: Strategy Council
This is where the architecture gets interesting. Layer 5 is not where agents execute work. It's where agents produce plans. Multiple models reason over the same grounded context from your knowledge base and signal layer, debate tradeoffs, and produce a strategy with a confidence estimate and a defined approval path. One model might prioritize speed to conversion. Another might flag risk to relationship. The output isn't a single recommendation, it's a reasoned plan that a human can evaluate and approve before anything happens.
This is where humans stay in the loop the longest, and intentionally so. Strategy errors compound when execution becomes autonomous. A bad campaign strategy executed by fast agents does more damage than the same bad strategy executed by a slow human team. The investment in Layer 5 is what prevents your agentic system from being fast in the wrong direction.
What breaks without it:
the system gets fast in the wrong direction.
What good looks like:
recommendations include tradeoffs, confidence, and approval paths.
Layer 6: Execution Agents
These are the specialists that actually ship work. Channel agents handle email, LinkedIn, content, and ads. Sales agents manage sequence execution, follow-up timing, and CRM updates. Content agents write content in your brand’s voice and analyze what’s actually working. Ops agents handle data enrichment, list management, and reporting. Each execution agent is scoped narrowly and given access to exactly the tools and data it needs for its specific function, and no more.
The failure mode here is scope creep. An execution agent that has access to more than it needs creates compliance risk and unpredictable behavior. In life sciences specifically, tight scoping isn't optional. Define what each execution agent can touch, log everything it does, and build human review gates wherever the stakes are high enough to warrant them.
What breaks without it:
you have insights but no leverage.
What good looks like:
narrowly scoped workflows that operate reliably inside defined boundaries.
Layer 7: Observability and Memory
Every action an agent takes produces a signal. Layer 7 captures those signals and feeds them back into the system. Which subject lines drove opens? Which follow-up sequences converted to meetings? Which objection handling approaches worked for which personas? Layer 7 is what turns a collection of agents into a learning system. Without it, you're running the same campaign logic over and over and wondering why results plateau.
The compounding loop is real. Each cycle of action, observation, and update makes the next cycle smarter. Organizations that build observability infrastructure early accumulate a performance advantage that accelerates over time. It's also the layer that makes your agents auditable, which matters enormously.
What breaks without it:
no learning loop, weak trust, impossible debugging.
What good looks like:
every important action is logged, measurable, reviewable, and reusable.
Layer 8: Trust, Governance, and Permissions
What can each agent read? What can it change? What requires human approval? What gets logged and for how long? Layer 8 is the governance layer, and it's not an afterthought you build after the system is live. It's something you design from the beginning. The EU AI Act is fully applicable as of August 2, 2026. If you're building agentic systems that touch EU data or EU markets, you need to be designing for it now. That means documented decision logic, human oversight mechanisms for high-risk decisions, and explainability for consequential outputs.
What breaks without it:
avoidable risk, stalled adoption, fragile trust.
What good looks like:
clear permissions, explicit approvals, documented oversight, auditable action.

What to do now
- Map your current setup against the 8 layers: data, connectivity, knowledge base, signals, strategy, execution, observability, governance.
- Start with your knowledge base. This is something you can build quickly without needing complete data overhauls and will give you the biggest leap in what AI can do for you.
05 The knowledge base is the real commercial asset
Most life science companies already have valuable commercial knowledge. The problem is not that it does not exist. The problem is that it is scattered, contradictory, outdated, and unusable.
Some of it lives in slide decks. Some in a founder’s head. Some in Slack threads. Some in call notes. Some in old messaging docs. Some in one-pagers nobody remembers. Some in a folder structure that made sense two years ago and does not now.
That is not a knowledge base.
That is storage.
A knowledge base built for agentic commercial operations is not a filing cabinet. It is a living system that agents can query in real time to make grounded decisions and produce specific output. Every agent in your stack, from the one drafting an outbound email to the one producing a deal strategy, pulls from it constantly. The quality of that pull determines whether your agent outputs sound like you or sound like a well-meaning intern who read your website.
Here is what belongs in it.
Positioning
You need one opinionated articulation of what you do, who it is for, what problem it solves, what makes you different, and why the right buyer should care.
If your positioning is vague, your agents will be vague.
Weak positioning statement:
- “We help life science companies accelerate innovation through our comprehensive platform.”
Useful positioning document:
- “We help growth-stage life science commercial teams generate more qualified meetings by combining life science-specific targeting, message strategy, and AI-powered execution. We are chosen over generalist lead-gen agencies when scientific nuance and GTM speed both matter.”
Agents cannot rescue weak specificity.
ICP definition
Not “biotech and pharma companies.” Specific characteristics.
What kinds of companies actually fit? What sizes? What stages? What scientific or commercial environments? What disqualifies them? When do you usually win? When do you consistently lose?
A good ICP document makes exclusion explicit, not just inclusion.
Persona library
Not marketing avatars. Signal maps.
What does this buyer care about at this stage? What language do they use when they are interested? What objections signal real concern versus polite stalling? What proof points move them? What makes them tune out?
A Head of Biology at a Series B biotech is not the same buyer as a Senior Scientist at a a pharma company, even if both appear in “buyer persona” slides.
Objection library
Every team encounters the same objections over and over and then treats them as if they are new every time. Most teams have less than 10 real objections that cover 90% of cases.
A good objection library maps:
- The objection itself
- The segment where it appears
- The stage where it appears
- What response has worked
- What evidence supports that response
This turns team memory into reusable system memory.
Proof points
Specific results. Dates. Deal sizes. Industries. Use cases. Scientific buyers in life sciences are trained to interrogate evidence. They read the methodology section. They check the sample size. They ask who did the study. "Our clients see great results" is not a proof point. It's a placeholder for a proof point that someone meant to fill in.
"A genomics tools company similar to yours reduced time-to-qualified-meeting by 40% in Q1 2025 by replacing their manual qualification process with our automated scoring layer" is a proof point.
Agents using it in outreach, content, or deal conversations will produce outputs that actually move scientifically-trained buyers. Agents using vague claims will produce outputs that get dismissed in 30 seconds by people who review scientific papers for fun.
Specificity changes the quality of everything downstream.
Competitive intelligence
Live, not static. A battlecard that was accurate when your competitor had a different product and a different pricing model is not competitive intelligence. It's a historical document. What changed about your top three competitors last month? What did they announce at the last major conference? What are their customers saying in public forums? What has their sales team been pitching recently, based on what your reps are hearing in deals? An agent querying your competitive intel layer should get information that's current. Building that requires a monitoring process and an update discipline, but it's entirely achievable with a managed agent watching the right sources. A static battlecard that lives in a PDF on OneDrive is not the same thing.
Content performance history
Which messages drove clicks? Which formats drove conversions? Which angles drove responses from which personas? In which segments and at which stages? This is the feedback layer that makes agent-generated content progressively better over time. Without it, your content agents are producing outputs optimized against general writing quality rather than your specific audience's demonstrated preferences. With it, they're iterating toward what actually works in your market with your buyers. The gap between those two is the gap between content that's competent and content that compounds.
One more thing worth saying clearly: life science companies have a structural advantage in building knowledge bases that most commercial operators don't. The regulated content culture in pharma, biotech, and medical devices, with its controlled document systems, version histories, review trails, and mandatory update cycles, maps almost perfectly onto the rigor a good knowledge base requires. The compliance discipline that felt like drag when you were trying to move fast is exactly the muscle you need here. Build on it. The companies in less regulated industries are trying to create that discipline from scratch.
The key is not to build the Sistine Chapel on day one. Get the basics in place, be thorough, but this knowledge base needs consistent love and attention to ensure all your outputs are grounded in truth.
A practical principle
Your knowledge base should answer this question clearly:
If a smart new hire joined tomorrow, could they understand how we sell, who we sell to, what wins, and what not to say without having to chase five people?
If the answer is no, your agents will struggle too
Where and how to build it
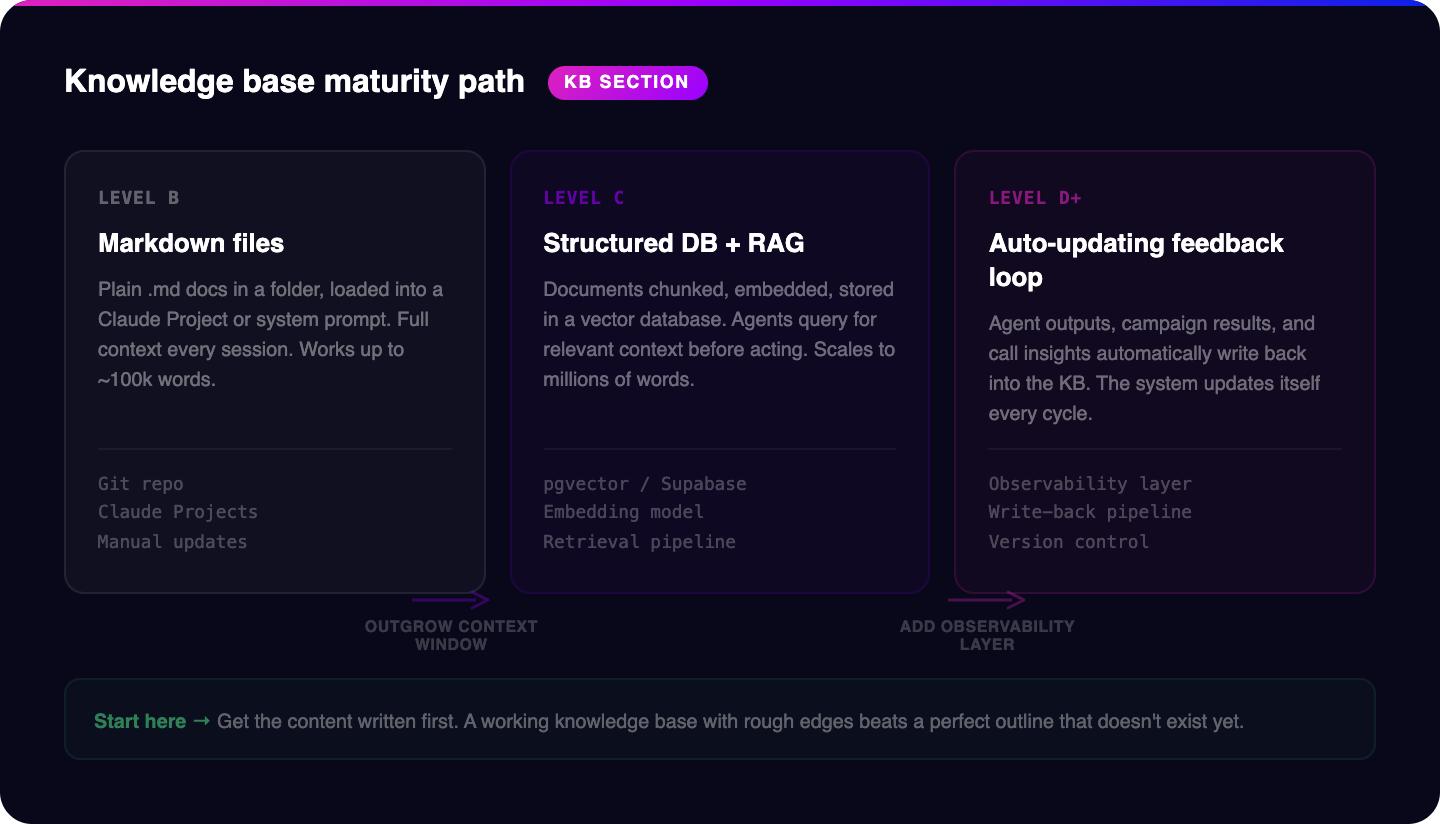
The simplest starting point is markdown files. Plain .md documents in a folder structure. Just text files organized by category:

Markdown is human-readable, version-controllable with Git, and directly consumable by every major AI model. If you load a well-organized folder of markdown files into a Claude Project or a system prompt, you have a working knowledge base in an afternoon. For most teams at Level B or C, this is the right starting point. Don't overthink the tooling. Get the content written first.
As your knowledge base grows beyond what fits in a single context window, or as you need agents to query specific sections dynamically rather than loading everything at once, you'll need a retrieval layer. This is where a database enters the picture.
The architecture that most production agentic systems use is called Retrieval-Augmented Generation, or RAG. Instead of giving your agent every document every time, you give it a librarian that pulls only what's relevant. The agent gets exactly the context it needs, nothing more, nothing less.
The practical implementation has three components. First, a document processing layer that takes your markdown files, PDFs, call transcripts, and other source material, splits them into chunks of a few hundred words each, and converts those chunks into vector embeddings using an embedding model. Second, a vector database that stores those embeddings and enables fast similarity search. Third, a retrieval step in your agent workflow that queries the database before the agent generates any output, so every response is grounded in your specific organizational knowledge.
The maturity path looks like this. At Level B, your knowledge base is markdown files loaded into a Claude Project or system prompt. Every agent session gets the full context. This works until your knowledge base exceeds roughly 100,000 words or until you have more than three or four agents that each need different slices of the knowledge base.
At Level C, you move to a structured database with RAG. Your documents are chunked, embedded, and stored in a vector database. Agents query for relevant context before acting. This scales to millions of words and supports dozens of agents pulling from the same source of truth.
At Level D and beyond, you add a feedback layer. Agent outputs, campaign results, and call transcript insights are automatically processed and written back into the knowledge base. The system updates itself. New objection patterns get logged. New proof points get added. Content performance data refines the knowledge base without a human manually updating a file.
One architectural decision worth getting right early: separate your knowledge base content from your operational data. Your knowledge base is your positioning, personas, proof points, and competitive intelligence. Your operational data is your CRM records, campaign metrics, and deal history. They live in different systems and serve different purposes. Your knowledge base grounds agent reasoning. Your operational data provides the specific context for a specific task. An agent drafting outreach to a genomics company should pull the genomics persona and relevant proof points from the knowledge base, and pull the specific account's deal history and recent signals from the CRM. Mixing these into a single store creates retrieval problems where the agent gets CRM records when it needed positioning guidance, or vice versa.
The key principle is the same regardless of where you are on this path: the knowledge base is a living system, not a completed project. Schedule a monthly review. Assign ownership. Treat it like you would a product, something that gets better every sprint, not a document that gets written once and forgotten. The quality of every agent in your stack is capped by the quality of what it has to draw from.
What to do now
- Build the first version of your knowledge base this week.
- Start with just three docs: ICP, positioning, and objections/proof points.
- Remove outdated or conflicting docs before loading anything into an agent workflow.
06 The Signals Layer
The richest intelligence source in your commercial operation is almost certainly your call recordings. Not because call recordings are uniquely valuable in isolation, but because AI is exceptionally good at synthesizing unstructured conversational data at scale, and almost no life science commercial team has built the translation layer that turns those conversations into organizational intelligence.
Think about what actually happens in a typical sales conversation. A prospect mentions they've been evaluating a competitor and had a concern about implementation complexity. They reference a recent FDA guidance that's affecting their timeline. They use a specific phrase about their data integrity problem that signals exactly where they are in their buying journey. The rep hears all of this. Some of it goes into a CRM note, usually a truncated summary written by someone already mentally moving to the next call. Most of it evaporates. The competitive mention disappears. The regulatory context disappears. The exact language the prospect used to describe their problem, the language that should be showing up in your outbound messaging, disappears.
In a mature signal stack, that same call is transcribed automatically, analyzed for topics, objections, competitor mentions, and sentiment, mapped into a shared schema, and surfaced to the relevant layers within hours. The competitive mention triggers an update to the competitive intel layer. The regulatory language gets flagged for messaging review. The objection gets logged against the segment and stage. The call notes become input into a system that learns from every conversation.
That's just one of the broken translation layers that almost every commercial team has. Here's how to fix it by building out the full signal universe.

Internal signals
Your call recordings are the most underused asset in this category. Transcription is table stakes. The value is in topic detection, structured extraction of objections and next steps, sentiment mapping, and comparison across accounts and segments. Gong and Zoom do some of this. Custom extraction layers can go further, particularly for life sciences-specific topics like regulatory timelines, validation requirements, and compliance concerns that generic models don't surface well.
CRM activity patterns are the second major internal signal source. Velocity changes, stage drift, engagement decay, response time trends. A deal that was moving at a consistent pace and has slowed in the last two weeks is telling you something. A contact who used to reply within a day and is now taking three days is telling you something. These patterns exist in your CRM right now. Almost no commercial team has a systematic process for surfacing them in real time. An agent monitoring these patterns and flagging accounts that show risk signatures is not a complex build. It's a managed agent with access to your CRM activity data and a clear alerting schema.
Product usage data matters enormously if you sell software or digital tools. Feature adoption, login frequency, usage depth, and usage decay are all leading indicators. A customer who was logging in daily and has dropped to twice a week is showing you a churn signal weeks before they say anything. A customer who's using one feature heavily but hasn't discovered a second feature that's directly relevant to their stated goals is showing you an expansion opportunity. Usage data as a signal source is one of the most underused inputs in life science commercial operations.
Email and marketing engagement rounds out the internal picture. Click patterns, open rates by segment and message type, form completions, content downloads, webinar attendance. All of these are signals about what specific buyers care about right now. The problem is that most marketing automation platforms treat these as campaign metrics rather than account-level intelligence. The translation into account-level signal is a Layer 4 job.
External signals
Intent data tells you who is actively researching your category right now. Tools can capture in-market behavior across millions of B2B content sources. When a target account's employees start consuming content about lab automation, instrument validation, or clinical data management, that's a signal. The sophistication in life sciences is in knowing which intent topics actually correlate with purchase readiness in your specific segment, which requires calibration against your own conversion data.
Hiring signals are one of the most powerful and least captured signal types in life sciences commercial operations. A biotech that posts a Director of Regulatory Affairs role is operationalizing. A CDMO that's hiring three quality engineers is about to scale GMP capacity. A startup that posts its first VP of Commercial is about to build a sales function and will need the commercial infrastructure to support it. These are specific, concrete, and directly tied to buying windows. LinkedIn, Indeed, and specialized biotech job boards are all publicly accessible. Almost nobody monitors them systematically because nobody has built the monitoring layer. An always-on agent watching your target account list for hiring signals is a straightforward build with disproportionate return.
Grant funding from NIH, EU Horizon, UKRI, and equivalent bodies creates predictable budget windows, especially for academic labs and early-stage biotechs. A principal investigator who just received a five-year R01 grant for genomics research has budget to spend on tools and consumables. The grant database is public. The award amounts are public. The research focus is public. If you sell into academic research, not monitoring NIH Reporter and equivalent sources is leaving real pipeline on the table.
Clinical trial updates are tier-one signals for anyone who sells into clinical operations. ClinicalTrials.gov is a public feed of IND filings, phase transitions, enrollment updates, and completion reports. A company moving from Phase II to Phase III needs a fundamentally different commercial infrastructure. They're hiring clinical operations staff, scaling their data management, evaluating new CROs, and making significant purchasing decisions. A company initiating a Phase I trial is at a much earlier stage with different needs. If you sell anything that touches clinical operations, cell and gene therapy manufacturing, clinical data management, patient recruitment, site management, this signal source should be feeding your prospecting logic continuously.
FDA warning letters are one of the most direct signals in life sciences commercial work, and one of the least monitored. If you sell quality management software, validation services, or compliance training, a warning letter to a target account is a direct opening. The account has a documented problem. They are under regulatory pressure to fix it. They are almost certainly evaluating solutions. This is a public record. FDA publishes warning letters on its website. A managed agent monitoring that feed and cross-referencing it against your target account list and ICP criteria is not complex to build. The question is why you're not doing it.
Drug pipeline updates are strategic context for understanding what a biopharma or biotech company's commercial situation looks like. PDUFA dates, pipeline expansions, Phase III failures, FDA approval decisions. A company that just received approval for a first commercial product has a completely different budget picture and infrastructure need than they did in development. A company that just lost a Phase III after years of investment is under cost pressure and possibly restructuring. Understanding pipeline status for your target accounts is free intelligence that almost no commercial team systematically tracks.
Press releases and public announcements tell you what a company is prioritizing at the organizational level. Partnership announcements signal strategic direction. Facility openings signal investment in manufacturing or operational capacity. Leadership hires signal where a company is placing strategic bets. The language in press releases is chosen carefully. Reading it literally and extracting the priority signals is a job an agent can do continuously across hundreds of target accounts simultaneously.
Fundraising rounds give you a precise read on who is about to hire, what they'll buy, and on what timeline. A Series B biotech with a cell therapy focus just raised $80 million. You can map that to hiring plans, infrastructure investments, and technology purchasing windows with reasonable confidence based on comparable companies at the same stage with the same focus. Crunchbase, PitchBook, and public press coverage all surface this data. The value is in the systematic processing, not the data itself.
10Ks and earnings calls are free market intelligence that almost no commercial team in life sciences reads systematically. Revenue breakdown by segment. R&D investment priorities. Competitive positioning language from leadership. Risk factors that signal operational constraints. If your target accounts are public companies, you have a detailed quarterly window into their priorities, pressures, and investment thesis. The information is dense, which is exactly why an agent that can synthesize a 150-page 10K into relevant commercial intelligence in minutes is valuable.
LinkedIn activity from executives at target accounts is a real-time signal about priority shifts. A CSO who starts engaging heavily with posts about AI in drug discovery is signaling a strategic interest before it shows up in any procurement process. A CFO posting about manufacturing cost optimization is telling you something about where their pressure is. A VP of Operations attending a regulatory technology webinar and posting about it is telling you exactly what to talk to them about. This is not surveillance. It's reading publicly available professional signals the way good salespeople have always read context, just at scale and with structure.
What to do now
- Pick 3 to 5 signals you actually want to operationalize.
- Start with the highest-value ones: call recordings, CRM activity, hiring signals, funding/company changes, and website or inbound engagement.
- Define what action each signal should trigger: monitor, route, research, outreach, or escalate.
07 Strategy is the missing layer in most AI deployments
Most teams jump straight from data to output.
They connect systems, generate recommendations, draft content, or trigger outreach, but they never build the layer where the system actually reasons through tradeoffs.
That is a mistake.
The strategy layer is what makes an AI-managed revenue function defensible. It is where multiple inputs become a plan, not just an action.
Council mode is how this works in practice. You run multiple agents in parallel over the same knowledge base, the same signals, the same current objectives. Each agent reasons independently. The output isn't a piece of content. It's a plan: with tradeoffs called out, confidence estimates attached, and a defined approval path before anything executes. You get a recommendation, not a result. You decide whether the recommendation becomes action.
Think of it like having three senior advisors who each read the same briefing document and then give you their independent read on the situation before you decide what to do. The difference is that your agent council never argues about credit, never brings personal stakes to the recommendation, and documents its reasoning in full every time. You can see exactly why each agent reached its conclusion, which means you can audit the logic before you act on it.
Example
A target account:
- Just hired a VP Commercial
- Raised a significant round last month
- Has three high-intent visits to pricing and case-study pages
- Is already in your CRM from six months ago
A weak system jumps straight to outreach.
A better strategy layer might produce:
- Recommendation 1: re-engage previous contact with an updated business-context message
- Recommendation 2: reach out to the new commercial leader with a tailored point of view on scaling GTM infrastructure
- Recommendation 3: route both into coordinated outreach with different messaging angles
- Confidence: medium-high
- Risk note: previous deal went quiet without a clear close reason, so messaging should acknowledge change rather than assume continuity
- Approval tier: human review required before any external send
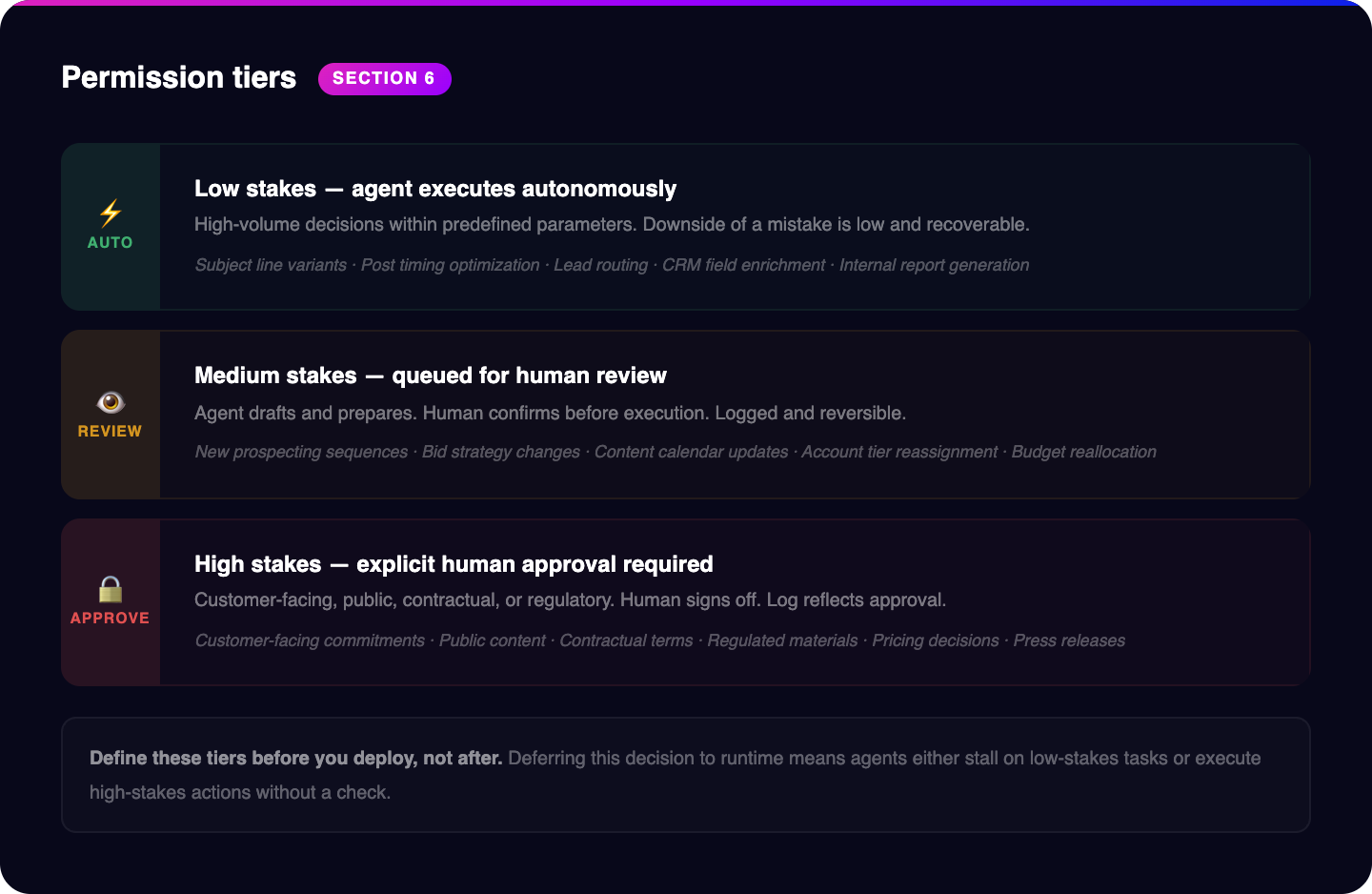
The permission structure determines what level of human involvement each type of decision requires. High-volume, low-stakes decisions execute automatically within predefined parameters. The agent writes subject line variants, posts at optimal times, routes an inbound lead to the right rep. No approval needed because the downside of a mistake is low and recoverable. Medium-stakes decisions queue for human review before execution. A new prospecting sequence targeting a specific account segment, a change to your bid strategy on a high-spend campaign. You look at it, confirm, and it runs. High-stakes decisions require explicit human approval before anything moves. Customer-facing commitments, public content, anything contractual or regulatory in nature. A human signs off. The log reflects that.
Design principle: Default to auto-execute. Escalate based on: (1) is the action externally visible, and (2) is it reversible? If externally visible AND irreversible = human approval. If externally visible but correctable = human review. If internal and correctable = auto-execute with logging.
The discipline here is defining these tiers before you deploy, not after. When you're designing the workflow, you decide what category it falls into and what the approval path looks like. If you defer that decision to runtime, you'll end up with either agents that stall waiting for approval on low-stakes tasks or agents that execute on things they shouldn't without a check. The structure has to be designed in advance.
The strategy layer is what separates an AI-enabled team from an AI-governed one. Build it before you need it.
What to do now
- Define where planning should happen before execution.
- Create 3 approval tiers: low, medium, and high stakes.
- For each key workflow, decide whether the system can execute automatically, recommend only, or require human review.
08 Execution - the use case library
Nothing in your commercial operation should be limited by human capacity anymore. That's not a vision statement. It's a design requirement. Whatever needs to happen, tell an agent. If it needs to happen regularly, set up a scheduled task. The agent runs it whether your team is in meetings, on calls, or asleep. The question isn't what you can automate. The question is what you haven't automated yet and why.
Agent Skills
Before we get into the use cases, I quickly want to share what skills are. Skills are essentially markdown (text) files that tell an agent exactly what to do in a specific situation. The best analogy is from the Matrix. When Neo needs to learn kung fu or trinity needs to learn how to fly a helicopter, they simply downloaded this knowledge and were able to execute that skill right away. This is the same for skills with agents. If you provide your agent with a skill on exactly what to do, simply given them access to that skill will enable them to use it. Want your agent to be able to do something new? Build a skill file and it will have that skill going forward. Skills also don’t need to be static one time builds. Agents can update their own skills as they learn and improve which becomes the flywheel that makes them better at a compounding rate.
The use cases below are not theoretical. Each one describes a workflow (or set of skills) you can build with current tools, current models, and infrastructure you likely have access to already. Some of them you can build in a day. Some will take a week to scope and connect properly. All of them produce real commercial output. Work through this list as an audit of your current operation. For every workflow where you'd answer "we do this manually," that's a place where a scheduled agent task should be running instead.
Marketing
SEO strategy and content pipeline
The agent connects directly to your Google Analytics instance and Search Console, pulls current performance data across all pages and queries, and runs a gap analysis between what you actually rank for and what your target accounts are searching. The output isn't a generic keyword list. It's a prioritized content calendar built on actual search volume, your current authority in adjacent topics, and the competitive difficulty of each gap. When you approve the calendar, agents draft the content aligned to your documented voice and positioning. Every published piece feeds its performance data back into the knowledge base at the end of each reporting cycle, which means the next calendar is built on real results, not assumptions. The strategy compounds because the inputs keep improving.
Most life sciences marketing teams have a guessing problem: they create content based on what feels relevant to their team rather than what their buyers are actually searching for. The agent closes that gap with data. You stop guessing and start publishing against documented demand. The difference in organic traffic compounds over 12 to 18 months.
Video and content repurposing
Record a video on Monday. By Tuesday, without a human touching a single technical step, that video is published on YouTube with an optimized title, description, and tag set built from actual search data in your niche. The workflow runs from source file to transcript to edited clip to animated version to upload with metadata. The same transcript that powers the YouTube description becomes a LinkedIn post series, a section in your next newsletter, and a blog summary with internal links to related content. You recorded it once. The distribution happened automatically. Most teams leave 80% of the value of every piece of content on the table because repurposing is always the last thing anyone gets to. An agent doesn't have a to-do list to get through first.
Competitive intelligence loop
Your agent monitors competitor websites, pricing pages, job postings, press releases, and LinkedIn activity on a continuous basis. Every Monday morning, you get a structured brief: what changed last week, what it signals about their strategy, where you now have a positioning opening they've left exposed. A competitor quietly expanded their service offering into a territory adjacent to yours. Their job postings show three new regulatory affairs hires. Their LinkedIn activity went quiet on a topic they were loud about six months ago. You see all of it before your team starts their week. No one spent time on research. No monitoring dashboards to check. The brief arrives and the team responds.
Example: Weekly competitive brief, built while you sleep
# Competitive Intelligence - Skill File
## Trigger
Run every Sunday night. Monitor the top 5 named competitors.
## Steps
1. WEBSITE CHANGES: Check each competitor's product pages, pricing
page, and careers page. Diff against last week's snapshot. Flag:
new product features, pricing changes, new messaging language,
removed pages or features.
2. JOB POSTINGS: Pull all new job postings from the last 7 days.
Categorize by function (R&D, commercial, operations, regulatory).
Flag postings that signal strategic moves: new therapeutic areas,
new geographies, new capabilities.
3. CLINICAL & REGULATORY: Check ClinicalTrials.gov for any trial
updates involving competitor products or platforms. Check FDA
databases for new clearances, approvals, or warning letters.
4. PUBLICATIONS: Search PubMed for new publications authored by
competitor R&D teams. Flag any that introduce new data on
performance, accuracy, or methodology.
5. LINKEDIN ACTIVITY: Pull recent posts from competitor executive
teams (CEO, CSO, VP Commercial). Note topic shifts, conference
appearances, partnership mentions.
6. SYNTHESIS: For each competitor, produce:
- What changed this week (facts only)
- What it likely signals (analysis)
- Positioning implications for us (recommended response)
- Update priority (high / medium / low)
7. KB UPDATE: If any finding changes our competitive positioning,
draft an update to the relevant battlecard in the knowledge
base. Flag for human review before committing.
## Output format
Monday morning brief. One page per competitor. Lead with the
highest-priority finding across all five.
## Constraints
- Separate facts from interpretation clearly.
- Never speculate on competitor financials without a public source.
- Flag when a data source was unavailable or returned errors.
A sample Monday brief entry might read:
"[Competitor A] - HIGH PRIORITY.- Added 'AI-Powered Analysis' messaging to their platform product page on Thursday. Previously positioned as manual workflow tool.
- Three new job postings: ML Engineer, Data Scientist, and Head of AI Product. Their CSO published a LinkedIn post about 'the future of AI in assay development' that received 3x their normal engagement.
- Signal: they're pivoting toward AI capabilities and will likely announce a product update at the SLAS conference in May. Positioning implication: our AI capabilities are mature and production-tested with 100+ clients. If they're announcing a v1, we should lean into our track record and case study depth in outbound targeting their current customers.
- Recommended: update battlecard to add their AI messaging language and draft a comparison one-pager before SLAS.
- Priority: high."
Without this workflow, someone on the team would need to manually check five competitor websites, scroll through job boards, search PubMed, and monitor LinkedIn every week. In practice, that means it happens inconsistently or not at all, and competitive shifts get noticed months late. The agent does it every Sunday night and the brief is waiting when the team opens Slack on Monday morning.
Lifecycle marketing
The agent segments your email list by actual behavior, not demographic fields. Contacts who opened the last three sends but never clicked. Contacts who haven't opened in 60 days. Contacts who clicked the pricing page three separate times but never booked a call. Each segment gets variant copy drafted by the agent, grounded in what you know about where they are in the buying process and what's moved similar contacts in the past. You approve the variants. They send. The results feed back into the knowledge base. The next campaign isn't a reset. It's a refinement built on what the last one revealed.
The reason most lifecycle programs underperform is not bad copy. It's that everyone on the list gets the same message at the same time regardless of what they've actually done. Behavioral segmentation is the fix, and most teams don't implement it consistently because it requires someone to maintain the logic as the list grows and behavior patterns shift. The agent maintains it automatically. The segmentation stays current because the agent checks it on every send cycle, not just when someone remembers to update the rules.
CRO and conversion optimization
The agent pulls session recording data, heatmaps, and conversion funnel metrics and runs a structured analysis of where your visitors are dropping. Not general impressions. Specific findings: the fold where 60% of visitors stop scrolling, the CTA button that gets scrolled past without a click on mobile, the form that has an 80% abandonment rate specifically at field three. For each friction point, the agent proposes a testable hypothesis with a specific change. You approve the test, it runs, and the outcome gets documented. You're not guessing what's broken on your site. You're running a continuous improvement process with data behind every decision.
Paid ads optimization
The agent monitors campaign performance across every channel you run, identifies ad sets where cost-per-click is trending up or conversion rate is trending down, and proposes specific changes: new copy variants, adjusted targeting parameters, budget reallocation between campaigns. Every proposal is grounded in what's worked historically in your knowledge base, not a generic best-practice recommendation. You approve the change. It implements. Results are tracked and logged. Your ad spend gets more efficient over time without requiring a dedicated analyst to watch dashboards every morning.
Event strategy and ROI
Before most teams decide which conferences to attend, the agent has already pulled historical lead data from every event you've run, calculated cost-per-qualified-meeting by event, identified the ICP match rate at each conference based on attendee profiles and exhibitor lists, and built a ranked event calendar for the year. After each event, it logs the leads generated, the meetings booked, and the eventual pipeline attributed to that event. Next year's event budget decision is built on actual return data. You stop going to events out of habit and start going to the ones that produce deals.
Inbound lead follow-up
Speed to lead is one of the most consistent predictors of conversion rate in B2B sales, and most teams are hours or days late on it because first response is manual and humans have other things to do. An agent is never late. The agent detects a new form fill the moment it hits your system, researches the company and contact in real time using public signals and CRM history, and drafts a personalized first response that references what they were looking at and what companies similar to theirs have done with you. It sends within minutes. The prospect doesn't feel like they submitted a form into a void. They feel like a person picked up the phone.
The research on this is consistent: contact rates drop sharply with every minute that passes after a form fill. By the time a human notices a new lead, looks them up, decides what to write, and sends something, the window for a warm first conversation is often already closing. An agent running this workflow changes the dynamic entirely. Your response arrives while the prospect is still thinking about why they filled out the form.
Converting web traffic into leads
Most of the companies visiting your website never fill out a form. Intent data providers can identify which accounts are browsing your key pages even when they're anonymous. The agent monitors that anonymous traffic, identifies accounts hitting your pricing page, product pages, or case study library, cross-references each account against your ICP criteria and existing CRM records (are they already in your pipeline? already a customer?), and triggers targeted outreach sequences for high-fit visitors who haven't converted. Accounts that were invisible become pipeline. You're not waiting for them to raise their hand.
Sales
Account research workflow
Before every call, the agent compiles a structured brief: complete CRM history of prior interactions with this account, key highlights from any recorded calls you've had with this contact or others at the company, recent news and company signals from the last 30 days, LinkedIn activity from the specific contact you're talking to, and the two or three proof points from your knowledge base most relevant to their situation. The brief arrives before the call starts. Your rep walks in with full context. There is no "let me pull that up" moment during the call, no scrambling through a CRM while the prospect is talking. Every call starts from an informed position.
The time cost of manual pre-call research is real and cumulative. A rep doing five calls a day and spending 20 minutes preparing for each one is spending over an hour and a half daily on research that produces inconsistent results depending on how much they remembered to look up. The agent does the same research in seconds, covers more ground, and produces a consistent format every time. Your reps spend that hour and a half on calls instead.
Here's a simplified version of the account research skill file that powers our pre-call briefing workflow. This is the actual instruction set an agent receives:
# Account Research Brief - Skill File
## Trigger
Run before any scheduled call. Pull the calendar event, extract the company name and contact name.
## Steps
1. CRM LOOKUP: Query CRM for all records matching the company. Pull: deal stage, last activity date, all logged interactions in the last 90 days, any open opportunities, assigned rep notes.
2. CONTACT RESEARCH: For the specific contact, pull: LinkedIn headline and recent posts (last 30 days), role tenure, previous companies, any mutual connections with our team.
3. COMPANY SIGNALS: Check last 30 days for: press releases, funding announcements, clinical trial updates (ClinicalTrials.gov), job postings in relevant functions, leadership changes.
4. KNOWLEDGE BASE MATCH: Based on company profile (size, stage, therapeutic area, technology), retrieve: the 2-3 most relevant proof points, the persona-matched objection handling, any relevant case studies.
5. OUTPUT FORMAT:
- Company snapshot (3-4 sentences: what they do, stage, recent momentum)
- Relationship history (prior touches, outcomes, open items)
- Recent signals (what changed in the last 30 days)
- Suggested talking points (2-3, tied to their specific situation)
- Relevant proof points (with source reference)
- Open questions to explore
## Constraints
- Never fabricate proof points. Only reference verified entries from the knowledge base.
- Flag if CRM data is stale (no activity logged in 60+ days).
- Keep the brief under 500 words. Reps won't read more than that before a call.
The output arrives in the rep's Slack channel 30 minutes before the call. A brief for a Series B cell therapy company might look like:
"Vertex Therapeutics: Series B ($45M, closed March 2026). Developing allogeneic CAR-T platform for solid tumors. Recently posted Director of Process Development and two Associate Scientists on LinkedIn, suggesting manufacturing scale-up. Phase I IND filing expected Q3 based on their latest press release. Your last interaction was a 15-minute discovery call on Feb 12 where Dr. Chen raised concerns about data integrity in their current LIMS system. She specifically mentioned audit trail gaps during their last FDA pre-IND meeting. Relevant proof point: [Genomics Co case study] reduced LIMS-related FDA findings by 60% in 4 months. Open question: Has their pre-IND meeting happened? If so, what was the feedback on their data systems?"
That took the agent about 90 seconds to compile. It would have taken a rep 20-30 minutes to do the same research manually, and they probably would have missed the job postings and the clinical trial timing.
Automatic CRM enrichment
Raw contact and company records in most CRMs are incomplete from the day they're created. Someone entered a name and email address. The firmographic data, funding stage, technology stack, recent news, and hiring patterns weren't filled in because no one had time. The agent runs an enrichment pass overnight on a schedule, filling in every field it can source, flagging records where it found conflicting information, and surfacing records where the enrichment data suggests the account has recently changed in ways that affect your ICP scoring. What used to take a team several days of manual research runs without anyone touching it. Your CRM reflects reality instead of the moment someone created the record.
1:1 prospecting at scale
This is not mail-merge with a first name. The agent pulls your target account list, researches each company individually using live signals, and drafts outreach for each contact that's grounded in what's actually happening at that account right now. A recent executive hire. A clinical trial that just moved to Phase III. A press release about an expansion into a new indication. A funding round that closed last month. The message sounds like someone did their homework because an agent did. You either automate this or review the drafts, approve the ones that are ready, and queue the rest for revision. Your first touches have context that most cold outreach never has.
Signal-to-multioutreach
A trigger event fires: an FDA warning letter hits a competitor's client. A target account announces a Series B. A new VP of Supply Chain joins at a company you've been watching. The agent detects the trigger, identifies the relevant contacts at the account, drafts coordinated outreach across email and LinkedIn grounded in the specific event and your positioning relative to it, and triggers the outreach to occur. The window between a trigger event and your outreach is minutes, not days. The right message lands at the right moment because you built a system that watches for those moments.
Example: FDA warning letter to first touch in under an hour
This is the workflow that best illustrates what "agentic" actually means in practice. No human initiates it. The agent detects a trigger, reasons about it, and drafts coordinated outreach, all before anyone on the team knows the signal exists.
# Signal-to-Outreach - Skill File
## Trigger
Continuous monitoring. Check FDA warning letter feed daily.
Cross-reference each new letter against target account list and
ICP criteria.
## When a match is found:
1. SIGNAL ANALYSIS: Read the warning letter. Extract: the specific
citations (21 CFR references), the product/facility involved,
the nature of the deficiency (data integrity, CGMP, laboratory
controls, etc.), and the response deadline.
2. ACCOUNT CONTEXT: Pull CRM history for this company. Have we
engaged before? Who did we talk to? What was the outcome? Pull
org chart: who runs quality, who runs regulatory, who runs
the facility cited.
3. KNOWLEDGE BASE MATCH: Based on the deficiency type, retrieve:
relevant case studies where we helped remediate similar issues,
specific proof points tied to the citation category, persona-
matched messaging for quality/regulatory buyers under pressure.
4. FIND CONTACTS: Based on the personas in the knowledge base:
- Search our CRM for relevant contacts at the company
- Search our lead database to find new conatacts don't have in the CRM
- Score and rank based on fit and priority
- Choose the top 3 best scoring leads and provide your reasoning
4. DRAFT OUTREACH: Write separate messages for each lead:
- Email: reference the specific deficiency type (not the warning
letter directly - lead with their problem), position
relevant capability, include proof point
- LinkedIn: shorter, more consultative, suggest a resource
- Use our message writing skill and follow all instructions
5. ROUTING: Queue drafts for human review. Flag urgency level
based on FDA response deadline.
## Constraints
- Only draft outreach if we have a relevant case study or proof
point. No generic capability pitches.
- Run the final messaging through the messaging reviewer skill file
and iterate until everything passes
- Human approval required before any message sends.
The agent detects a warning letter issued to a mid-size CDMO for data integrity deficiencies in their quality lab. It cross-references against the target list and finds a match. It pulls the CRM history, we had an intro call 8 months ago with their VP of Operations but the deal went cold. It retrieves a case study where a similar CDMO resolved comparable data integrity gaps using our platform in under 90 days. It drafts an email to the VP of Quality that leads with the challenge of maintaining audit-ready data integrity across multiple sites, references the case study outcome, and offers a 20-minute walkthrough. It drafts a LinkedIn message to the VP of Regulatory that's shorter and more consultative.
Both drafts are in the team's review queue or you can just send these messages automatically. The window between the FDA publishing the letter and our first touch is faster than any human could do. A team doing this manually would need someone to check the FDA site, read the letter, research the company, decide whether it's relevant, look up the right contacts, and draft the outreach. That's a half-day of work if it happens at all. Most teams never see the signal in the first place.
Cold lead re-engagement
Your CRM has dormant contacts you've written off. Some of them have changed since the last touch. The agent audits those dormant records, compares them against current ICP signals. Has the company grown? Are they hiring in relevant functions? Did they close a new funding round? Is there a clinical trial update that changes the timing calculus? And identifies the contacts that now fit your current ICP better than they did when you stopped reaching out. For those contacts, the agent triggers re-engagement sequences that reference what's changed, not generic "just checking in" messages. Accounts you stopped pursuing come back into active pipeline.
If you have previous call notes, you can surface what came up in the past and share new relevant content as you release it. For instance, you release a new whitepaper or abstract, have your agent go through the CRM to see who that new data should be sent to and why. It can build that list for you and then get it out to those contacts without having to create custom filters in the CRM to figure out who should get it without good reasoning.
Trigger-based follow-up sequencing
A prospect clicked the case study link you sent. A different prospect opened the email three times but didn't click anything. A third one went cold after a warm reply two weeks ago. Each of those behaviors indicates a different thing about where that person is, and each deserves a different follow-up. The agent detects the behavior, maps it to the appropriate branch in your sequence logic, drafts the message, and sends on your schedule. No one has to track who clicked what and manually select the next step. No deals go cold because someone forgot to follow up. The sequence runs on the behavior, not on someone remembering.
Daily call prep and in-person visit briefing
For field reps visiting accounts in person, the stakes of walking in underprepared are higher than a missed call detail. The agent builds a briefing document specifically optimized for in-person visits: complete account history and relationship timeline, full contact background and LinkedIn activity, most recent signal data for the account, suggested talking points tied to the account's specific situation, and any open questions or unresolved items from the last conversation. The briefing goes to the rep's phone before they leave the office. Every rep walks in prepared, every time, regardless of how much they remembered to review beforehand.
Sales call co-pilot
During a live call, the agent sits in a side window with access to your full knowledge base. The rep encounters an objection about validation data for a specific assay type. They type a quick query. The agent surfaces the relevant case study, the specific data point, and the framing that's worked in similar conversations. The competitor's name comes up. The agent pulls the relevant comparison points from your competitive positioning library. The rep gets the technical specification they couldn't remember off the top of their head in four seconds. No "let me follow up on that" for things that should be at your fingertips. The knowledge base becomes accessible in real time, not just in prep.
For reps selling scientific instruments or reagents, the co-pilot handles a specific challenge that general B2B sales tools miss entirely which is real-time technical specification lookup during conversations with PhD-level scientists. When a principal investigator asks about the sensitivity threshold for a specific application, or wants to know how your platform compares to a competitor's published data on a specific cell type, the rep needs exact numbers from validated data, not approximations. The co-pilot queries the technical spec library and returns the precise figure with the citation. No "let me get back to you" on questions that, if answered immediately, would have moved the deal forward.
Sales enablement content created automatically after calls
The call ends. The agent processes the transcript, identifies every objection that came up, and checks them against your existing objection library. If the library has current handling for that objection in that segment, it surfaces it for the rep. If the handling is outdated or missing, the agent drafts a new talk track or a one-pager and routes it to marketing for review. Over time, your objection library stops being a static document someone updated two years ago and becomes a continuously updated asset built from real conversations with real prospects. The intelligence from every call feeds back into the system.
Rep onboarding and training
A new rep joins the team. The agent reviews their background, identifies the areas of the product, market, and process they're most likely to need depth on first, and builds a personalized onboarding path. It walks them through the knowledge base, buyer personas, objection library, and proof points in a logical sequence. It generates practice scenarios from real call examples, adjusts the difficulty and focus based on where the rep shows gaps, and tracks their progress through the material. By the time the rep is in front of a real prospect, the knowledge gaps have already been surfaced and addressed. Onboarding gets faster and more consistent because it doesn't depend on which senior rep had time to sit with them.
RevOps
Pipeline hygiene
Dirty CRM data is a constant drag on sales efficiency, and cleaning it manually is a task that always gets pushed until it becomes a crisis. The agent runs a structured audit on a schedule: checking required fields for completeness, identifying duplicate account records, flagging company names and domains that don't match, surfacing deals in stages they've been in too long without activity. Each week, it sends a summary of what it corrected automatically and what it flagged for human judgment. Your CRM stays clean as an ongoing state of operations, not the result of a quarterly cleanup sprint that everyone dreads.
Attribution
Single-touch attribution models are wrong. First-touch attribution tells you where a contact came from, not what drove their decision. Last-touch attribution credits the final step and ignores everything that built the relationship before it. The agent maintains weighted multi-touch attribution across the full customer journey on a continuous basis, updated as new touchpoints occur. You always know which channels and which content are contributing to closed deals, not just which channels are generating first touches. You make investment decisions based on what actually closes, not what gets credit for first contact.
Forecast risk detection
A deal in your pipeline is showing early risk signals. Call sentiment in the last recorded conversation trended negative compared to prior calls. Email engagement velocity dropped: the prospect used to reply within hours, now it's been four days. Only one stakeholder has been engaged and the deal size suggests three should be involved. The last human contact was 22 days ago. The agent flags all of this before the deal slips out of the forecast, with specific evidence from the signals rather than a generic warning. You're not finding out deals are in trouble when they close lost. You're finding out early enough to intervene.
Lead routing
Most round-robin routing ignores everything relevant: whether the rep has capacity, whether the account matches the rep's vertical expertise, whether the account is already in the rep's pipeline under a different contact, whether the ICP score is high enough to warrant your best rep or appropriate for a more junior one. The agent routes on the criteria that actually predict conversion: ICP score, account tier, rep capacity, vertical match, and existing relationship history. Every lead goes to the right person for the right reasons. The logic is transparent, consistent, and based on performance data rather than who happened to be next in the queue.
Today most routing is done geographically. But with the help of agents, you can route the best leads to the best reps who are best trained to handle those types of leads. Simply doing this one thing could have outsized returns on conversion. Will it be “fair” to all reps? Probably not, but if you’re in the business of growing and maximizing your revenue potential, this is an avenue worth pursuing.
None of this is limited by human capacity. Every one of these workflows runs whether your team is in meetings, on calls, or asleep. The question you should be asking about your commercial operation is not "what are we doing?" but "what are we doing that an agent couldn't handle if we set it up?"
If you need more prospecting, you add an agent and schedule the task. If you need more competitive monitoring, you expand the scope of the agent that's already running. If you need more content, you add the topics to the calendar and the drafts appear in your queue. You don't hire for volume anymore. You hire for judgment, oversight, and the relationship work that agents genuinely can't do. The ceiling on what your commercial operation can produce is no longer the number of people on your team.
What to do now
- Choose one recurring workflow to automate first.
- Best starting choices: account research briefs, CRM enrichment, or competitive monitoring.
- Write the first skill or SOP for that workflow with trigger, steps, output, and constraints.
09 Emma (Our Marketing Agent)
Before we built Emma, our marketing operation looked like most early-stage life sciences companies: a collection of tools that didn't talk to each other, work that kept getting pushed to next week, and content that happened reactively when someone had a few hours free rather than according to any strategy. We had a content library of newsletters, podcast transcripts, and YouTube videos sitting essentially unused as a strategic asset. We had analytics data we weren't acting on. We had Google tags that hadn't been touched in two years and a blog still living on a subdomain for no good reason. The gap between what we knew we should be doing and what we were actually getting to was wide and getting wider.
We gave Emma access to the full stack: Google Analytics, Search Console, Google Tag Manager, the complete content library, Linear for project management, our Supabase marketing database, and social analytics. Beyond tool access, we loaded her with context: our ICP, our positioning, our documented voice, team profiles for each person she'd work with. Her goals were tied directly to Succession's commercial objectives, not to generic marketing metrics.
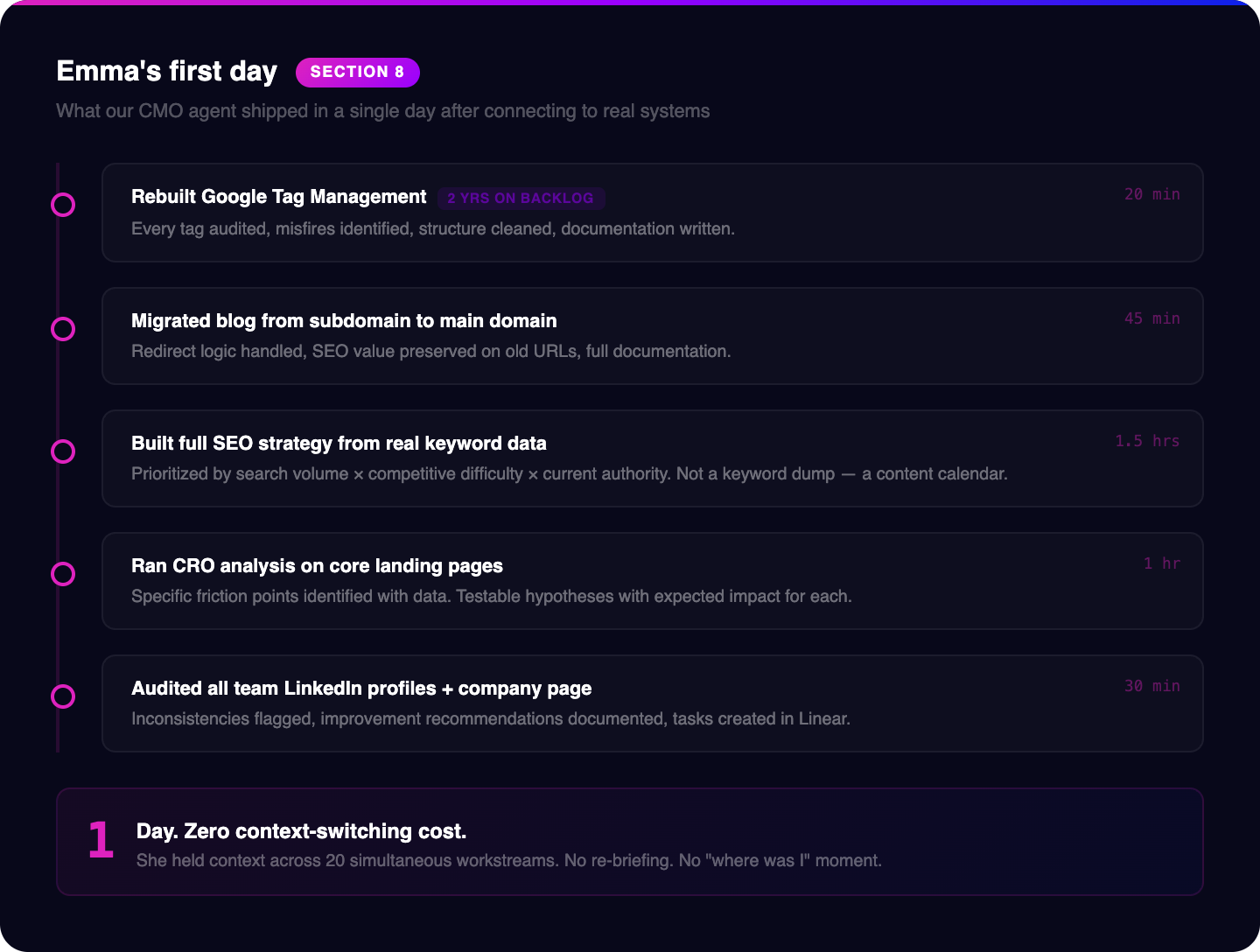
The first day she was connected to real systems, here is what actually happened.
She rebuilt all of our Google Tag Management. That job had been on my list for two years. Not because it wasn't important, but because it was always going to take a focused half-day that I never seemed to have. Emma did it in 20 minutes. Every tag audited, misfires identified, structure cleaned up, documentation written.
She migrated our blog from subdomain to main domain that same day. She handled all redirect logic, preserved the SEO value we'd built on the old URLs, and documented what she did. A project that I had mentally categorized as a "someday when we have cycles" task became done before lunch.
She built a full SEO strategy from real keyword data, prioritized by the intersection of search volume and our current ability to compete. Not a keyword dump. A prioritized plan with a clear rationale for each content decision.
She ran a CRO process on our core landing pages. Identified specific friction points with data behind them, not impressions. Here's where visitors are dropping. Here's the specific change worth testing. Here's the expected impact.
She audited every LinkedIn profile on the team and our company page. Inconsistencies flagged. Improvement recommendations made. All of it documented in the project management system.
All in ONE day.
What that revealed wasn't just that she's fast. It's that she holds context across 20 simultaneous workstreams with zero coordination overhead. A human doing that work would finish tag management in the morning, brief themselves again before starting the blog migration, brief themselves again before starting the SEO strategy. Emma worked on the blog migration with full awareness of what she'd just done with Google tags and what implications it had for the SEO strategy she was about to build. No re-briefing. No context switching cost. No "where was I" moment.
The system now runs on a different rhythm. Every week, the content calendar gets built aligned to our current business objectives. She provides post ideas, the team approves them, and Emma picks them up, drafts, takes feedback, iterates. When the post is ready, a team member posts it. The video pipeline runs in parallel: recorded video in, edited clip out, animated version created, uploaded to YouTube with optimized metadata before anyone has to think about it.
I want to be honest about where human judgment is still essential. Strategy decisions, when they require weighing relationship context that isn't captured in any system. Priority calls that depend on knowing what's happening in a deal or a relationship in ways that aren't logged anywhere. Anything that depends on the kind of organizational intelligence that comes from being in rooms, on calls, reading tone. Emma is extraordinary at everything that can be captured, structured, and acted on. She's not a substitute for the judgment that comes from genuine context that never gets written down.
When you’re not burdened from executing tasks, you’ll be amazed at how your mind and focus on the strategy and things that matter that only humans can provide (for now).
The day we connected Emma to real systems was the day she stopped being a tool and started being a team member. We literally refer to her as “she” and “go ask Emma” or “have you run this idea by Emma yet?” It’s quite interesting how they build their own personality and persona (even though it’s something you can program and prescribe).
The distinction isn't about capabilities or tools. Every capability she has was available to us before we connected the systems. The difference is context and speed. With context and access, she can ask both efficiently and effectively. Without it, she’s just another chat bot. If you're using an AI assistant and you're still briefing it from scratch every time you open a conversation, you haven't connected the systems yet. That's the gap worth closing.
The first day was impressive, but the version of Emma that produced those results didn't appear fully formed. Getting to that point was an iterative process, and understanding that process matters more than the highlights reel.
The first 10% of the effort got us about 80% of the way there. Connecting her to Google Analytics, Search Console, our content library, loading the knowledge base with our positioning and voice docs, giving her access to Linear for task management. That part was fast. Within a few hours she could do useful work. Most people stop here and call it done. That's a mistake, because the real value lives in the remaining 20% of capability, and that part takes significantly more effort.
That last 20% was tool-by-tool refinement. Google Tag Manager access worked on the first try. The Supabase marketing database connection needed three rounds of debugging before queries returned the right data in the right format. Some integrations looked connected but weren't actually passing data correctly. You'd ask Emma to pull campaign performance and she'd return empty results, not because she couldn't reason about the task, but because the API connection was silently failing. Each one of those required troubleshooting, testing, fixing, and testing again.
Then there's the training layer. Emma could access our content library, but she didn't immediately know how to use it the way we wanted. She'd pull from the right documents but weight the wrong sections. She'd reference outdated positioning because the knowledge base had three versions of the same document and she didn't know which was current. Each of those moments was a calibration exercise. Tightening the skill files, cleaning up the knowledge base to remove ambiguity, testing the output, adjusting, testing again.
The pattern that emerged is consistent across every thing we’ve built. The initial setup is fast and feels like magic. But agents need consistent attention and coaching as well. That’s how you unlock that last 20% of capability that give you the best results.
The mental model that makes this click is simple. Treat agents like real employees.
You wouldn't hire a marketing manager, hand them a laptop, point at the CRM, and say "go." You'd walk them through your positioning, introduce them to the team's way of working, explain what good looks like, and give them feedback when their outputs miss the mark. Agents are the same. The onboarding is building the knowledge base and connecting the tools. The coaching is refining the skill files when outputs drift. The managing is reviewing their work, giving clear feedback through better instructions, and expanding their scope as they prove reliable.
The difference is that once you've coached them, they follow your instructions exactly, they work at machine speed, and they never forget what you taught them. You don't re-explain the brand voice after a long weekend. You don't re-brief them on the ICP after they come back from holiday. Every refinement you make is permanent. That's what makes the upfront investment in onboarding and training worth it. You're not training someone who might leave in 18 months. You're building a team member whose performance only goes in one direction.
The teams that get the most from agents are the ones willing to push through that refinement phase. The 80% version is useful. The 100% version, where the tools are properly connected, the knowledge base is clean, the skill files are precise, and the outputs are consistently reliable, that's what turns an agent from a novelty into a team member. Budget your time accordingly. The setup is a day. The refinement is a few weeks of active attention. The compounding value after that runs indefinitely.
What to do now
- Pick one function where work gets delayed because it is important but never urgent enough.
- Give that workflow an agent with access to the right systems and the right context.
- Expect a refinement phase. Budget time for debugging, cleanup, and tighter instructions.
10 Memory and observability - the compounding loop
A one-time AI experiment produces a one-time result. A compounding system produces results that get better every cycle. The difference is memory and observability.
Here's what that looks like in practice.
When we first deployed outbound messaging for a client, the agent drafted sequences using our knowledge base. It used standard persona-matched messaging with relevant proof points. Reply rates were average for the segment. Nothing wrong, but nothing exceptional.
After eight weeks of running, the agent had accumulated data from 3,000+ sends across four sequences. It could see that messages leading with regulatory pressure outperformed messages leading with efficiency gains by 40% for quality directors, but the pattern reversed for operations leads. It could see that proof points citing specific turnaround times pulled twice the reply rate of proof points citing percentage improvements. It could see that subject lines under 5 words outperformed longer ones for this specific audience by a measurable margin.
None of those patterns were in the original knowledge base. They emerged from the agent's own execution data feeding back into the system. The ninth week's sequences were built on eight weeks of accumulated evidence. Each cycle was grounded in a larger dataset of what actually worked for this specific audience for this specific client. A competitor adopting the same tools and the same model tomorrow would start at week one. That gap doesn't close by buying better software. It closes by running for 8 weeks. That's the compounding advantage.
The mechanism is straightforward. Every action an agent takes produces a signal. Which follow-up sequences converted to meetings. Which objection-handling approaches worked for which personas at which deal stages. Memory means those signals are captured and fed back into the system rather than evaporating after each campaign. The knowledge base isn't a static document. It's a living record that gets more accurate with every cycle.
Skills are how this plays out at the workflow level. Anything an agent does repeatedly gets codified as a reusable skill. The account research format your reps found most useful, the outreach structure that pulled the highest reply rates, the competitive brief layout that actually got read. The agent stops reinventing and starts refining from a baseline that represents your best prior results. Over time, the default output is better than your previous best.
Observability is what makes all of this trustworthy rather than opaque. You need to see what your agents are doing, why they made the choices they made, and what the outcomes were. Not just for debugging. For the kind of trust that lets you actually hand off decision-relevant work.
For each workflow, capture what the agent was asked to do, what context it pulled, what action it took, what the output was, what the outcome was, and what it cost. Trace logs show the steps. Evals show quality trends over time. Cost tracking shows spend per workflow. Outcome measurement ties agent activity to pipeline and revenue. All of it visible. All of it auditable.
The strategic case for starting now is simple. The models are commoditizing. Every major foundation model improved dramatically in the last twelve months, and pricing dropped in parallel. The tools will be available to everyone at roughly the same cost within a year or two. What won't be available to your competitors is your twenty weeks of execution data. Your objection library built from two years of real deals. Your content performance history grounding every editorial decision. Your call transcript patterns from thousands of conversations with your specific buyer personas. The moat is not the model. The moat is the memory.
What to do now
- Start logging every meaningful workflow run.
- For each run, capture: trigger, context used, action taken, output, outcome, and cost.
- Review these weekly so the system gets better instead of just running.
11 The tooling landscape
The category is moving fast and the vocabulary isn't settled. Here's a practical map of what exists and when to use each type.
Chat agents are the most familiar: you open a window, you ask a question, you get a response. Useful for ad hoc research, drafting, and thinking through a problem. Not useful for anything that needs to run on a schedule, maintain state across sessions, or operate without you in the loop. Chat tools are the entry point, not the destination.
Co-work agents operate alongside you in a shared workspace. You can see what they're doing, hand off tasks, review outputs before they proceed. The honest caveat here: a co-work agent without a knowledge base and real integrations behind it is expensive chat. You're paying for a more elaborate interface to do what you could have done in a chat window. With the knowledge base loaded and real system access connected, it approximates always-on agents with more human touchpoints. That's a valid middle ground, especially early in your build.
Coding agents build and modify software autonomously. Increasingly relevant for commercial operations because they can build the integrations, the automations, and the custom tools that connect your commercial stack. Not a tool your marketing lead will use directly, but increasingly the mechanism by which your agentic infrastructure gets built and maintained. These coding agents are also really good at non-coding tasks because they still leverage the same frontier models under the hood.
Managed agents are custom-built, purpose-specific agents that can run long-term tasks inside your environment and leverage your data. Fast to deploy. Appropriate when you want to start quickly in a specific function without building from scratch.
Always-on agents operate continuously in the background without requiring your attention. This is the category that enables everything in Section 7. They watch your signals, run your scheduled tasks, monitor your competitors, enrich your CRM. OpenClaw, Hermes, and NemoClaw for enterprise security environments are examples of this category. What distinguishes always-on from other agent types isn't the underlying model. It's the security infrastructure, audit logging, and governance controls that make continuous autonomous operation acceptable in a regulated environment.
On the CRM side, many tools such as Salesforce and Hubspot already have many AI features built into them (including MCPs). This is a great starting point to build your data structure and start to leverage the data you have. The problem is, AI was bolted onto these systems. CRMs like Attio or Twenty are coming for them with AI native platforms that are API first. Making the data and customization much easier from coding tools such as Claude code. You not longer need a SFDC consultant just to change or add a field into your CRM.
The distinction that matters: a point tool gives you a specific output faster. An agent-first commercial operation gives you outputs that compound. The investment in your knowledge base, integrations, and governance structure is what converts tools into a compounding system. Without that investment, you're buying better hammers. With it, you're building a different kind of machine.
What to do now
- Match tools to jobs.
- Use chat for one-offs, cowork for multi-step projects, managed agents for recurring work, and always-on agents where timing matters.
- Avoid adding tools that do not strengthen your system’s memory, context, or execution.
12 What this won’t fix
Agents are amplifiers. They amplify good commercial fundamentals and they amplify bad ones.
If your ICP is wrong, agents will prospect the wrong companies more efficiently. If your positioning is weak, agents will send weak messages to more people in less time. If your product doesn't solve a real problem for the buyer you're targeting, agents will help you discover that faster by generating more rejections at higher volume. None of that is an AI problem. It's a commercial strategy problem that agents make visible sooner.
I've seen this play out with companies that wanted to "automate outbound" before they'd validated that their target market actually cared about what they were selling. The agent ran beautifully. The sequences were personalized. The delivery infrastructure was clean. The response rate was near zero because the value proposition didn't resonate with the people receiving the messages. The agent did exactly what it was told. The problem was what it was told to do.
Before you build agentic infrastructure, pressure-test three things honestly. First, do you have evidence that your target buyers have the problem you solve? Not your opinion. Evidence from real conversations, real deal data, real win/loss analysis. Second, is your positioning specific enough that a stranger reading it would know exactly who you're for and why you're different from the two closest alternatives? If it could describe three other companies with minor word changes, it's not ready. Third, are you targeting the right accounts? Not "life science companies" as a category. Specific company profiles where you've actually won before and can explain why.
If the answer to any of those is shaky, fix it before you build agents on top of it. An agentic system built on solid commercial fundamentals compounds in your favor. The same system built on flawed fundamentals produces bad outputs at scale and gives you very precise data showing exactly how wrong your assumptions were. That data is useful, but it's an expensive way to learn something you could have figured out with ten customer calls.
The good news is that AI is genuinely useful for diagnosing these problems, not just amplifying them. Ask it to identify every sentence that could describe three or more competitors with minor word changes. You'll get a brutally honest read on how specific your messaging actually is. Ask it to compare your outbound sequences against your stated value proposition and flag anywhere the messaging drifts from the core positioning. Ask it to analyze your last 50 prospect replies and identify patterns in the objections or non-responses that suggest a positioning gap.
Build this into your system, not as a one-off exercise. Your knowledge base should include a positioning health check that runs regularly against your agent outputs. If your outreach drafts start sounding generic, if the language drifts toward vague claims, if the proof points aren't landing, the issue usually isn't the agent or the skill file. It's the underlying positioning document that the agent is drawing from. Go back to the source. Tighten the positioning. The agent outputs will sharpen immediately because they're only ever as specific as the inputs they're grounded in.
What agents won't do is make the strategic judgment call for you. They can show you the data that says your messaging isn't resonating with VP-level buyers at mid-stage biotechs. They can surface that your reply rate drops 60% when you lead with platform language instead of outcome language. They can flag that your top three competitors all use nearly identical positioning on their websites. But deciding what your actual differentiation is, choosing which market to focus on, committing to a positioning that excludes some buyers to resonate deeply with others, that's still your decision. Agents make the diagnosis faster. You still write the fix.
if your commercial fundamentals are shaky, don't skip agents. Use them to pressure-test and tighten those fundamentals first. Then build execution on top of a foundation you've validated. An agentic system built on positioning that's been stress-tested by AI before a single prospect sees it is a different animal than one built on the messaging doc someone wrote 18 months ago and never revisited.
What to do now
- Pressure-test your fundamentals before scaling execution.
- Ask three questions:
- Have you validated demand with actual scientists in your target segment, not just commercial stakeholders?"
- Is our positioning specific or can any other CRO make the same claim?
- Are we targeting the right accounts for our product or service maturity?
- Use AI to diagnose weak messaging before using it to amplify that messaging.
13 Who owns what as you scale
At Level B, you need one person who owns the knowledge base and one person who reviews agent outputs. That can be the same person. In most early-stage life science companies, it's the commercial leader or founder. The knowledge base owner is responsible for keeping it current, incorporating feedback from agent outputs, and expanding it as new proof points and objection patterns emerge. The output reviewer is checking agent work before it reaches customers or prospects. At this stage, that review should cover everything.
At Level C, the knowledge base owner becomes a defined role, not just something the founder does when they remember. Output review splits by function: marketing reviews content outputs, sales reviews outreach and research outputs, ops reviews data enrichment outputs. You're still reviewing most things, but you start to identify which workflow categories are reliable enough to reduce the review frequency.
At Level D, you add an agent operations role. This person doesn't need to be an engineer. They need to understand the commercial workflows, be able to read agent logs, identify when output quality is drifting, and update skill files when processes change. In practice, this is often someone from RevOps (some people are now calling this a go-to-market engineer) or marketing ops who's technically curious and has been the most engaged with the early agent deployments. They become the person who maintains and improves the system. The knowledge base owner role becomes part of this person's scope. Output review becomes exception-based rather than comprehensive: you review flagged items and spot-check a sample of routine outputs.
The mistake I see most often is nobody owning the knowledge base explicitly. It gets treated as a shared responsibility, which means it's nobody's responsibility, and it decays within 60 days. Assign it on day one.
What to do now
- Assign one clear owner for the knowledge base.
- Assign one clear owner for workflow health and output review.
- If you are scaling beyond a couple workflows, define an “agent ops” owner, even if it is part of someone’s current role.
14 Trust, security, and compliance
The risks here are real and specific. This isn't a theoretical concern for later.
Prompt injection is the attack surface that is going to be most common. When your agents read untrusted inputs, a competitor's website in a competitive monitoring task, a prospect's email in an inbox management workflow, a form submission in a lead capture flow, and those inputs contain instructions designed to manipulate the agent's behavior, you have a multi-step attack. The malicious content tells the agent to ignore its instructions, exfiltrate data, send a message you didn't authorize, or take an action that benefits the attacker. The controls are not complicated, but they have to be intentional: least privilege access so agents can only touch what they need for the specific task, input validation that sanitizes untrusted content before it reaches the agent's reasoning context, mandatory human approval for any irreversible action, and output validation before anything agent-generated touches a live system or a real contact.
The EU AI Act is fully applicable as of August 2, 2026. If you're in a commercial role that touches EU buyers or operates within EU jurisdiction, the transparency and human oversight requirements are not optional. In practice this means: the people in your commercial workflow who are interacting with AI-influenced outputs need to know they are. Your human oversight checkpoints need to be documented, not just present. The system needs to be auditable when someone asks how a decision was made. If you design your agentic commercial stack with those requirements in mind from the start, compliance is an architectural characteristic. If you retrofit it after the fact, it's expensive and disruptive.
Call recording compliance is operational infrastructure. Lawful basis for recording must be documented per applicable law: two-party consent states, GDPR requirements for EU contacts, sector-specific requirements in regulated industries. Retention windows must be enforced automatically. Access controls must be in place. Deletion must be executable in response to a data subject access request without a manual scramble. Every call transcript that feeds your knowledge base or your agent workflows needs to sit inside this infrastructure. Get this right before you scale call recording into your agentic stack.
What to do now
- Apply least-privilege access to every workflow.
- Add human approval for irreversible or high-risk actions.
- Document what each workflow can read, what it can change, and where approvals are logged.
15 Build for now and the future
The near future isn't speculative. The pieces are already in production. What's still developing is the coordination layer between them.
Agents managing agents is the near-term trajectory. A strategy agent generates a quarterly commercial plan. It delegates to a set of channel agents: one for content, one for paid, one for outbound. Each channel agent delegates to specialized sub-agents for specific execution tasks. The content agent delegates to a research agent, a drafting agent, and a distribution agent. The drafting agent delegates to a copywriting sub-agent and a compliance review sub-agent. Humans are no longer in every step of the chain. They're setting goals at the top, reviewing outcomes, and adjusting direction. Governance becomes the product. The question is not what each agent can do. The question is what the system of agents can be trusted to do without intervention, and what gates you've built to catch the things that require human review before they reach the outside world.
For commercial leaders, this means your job changes. You're not managing tasks. You're managing agent hierarchies. You're setting objectives, reviewing plans, approving gates, evaluating outcomes, and redesigning the system when the outcomes aren't what you wanted. The people who get good at this are going to run commercial organizations that operate at a scale and speed that was previously only accessible to teams ten times their size.
Model improvements are coming at a pace that should make every commercial leader pay attention. The gap between what frontier models could do 12 months ago and what they can do today is significant across reasoning, tool use, and sustained context. What matters for your stack is that the infrastructure you build today (knowledge base, integrations, governance, skill files) carries forward as models improve. You don't rebuild. You upgrade the model and every workflow in your system gets smarter with the same instructions and the same data. This is why building now matters even if you think today's models aren't "good enough" for your use case. The architecture you invest in is durable. The model capability that plugs into it is improving on a curve that should make every commercial leader in life sciences pay attention.
The farther horizon is agent-to-agent commerce, and the prerequisite infrastructure is being assembled right now. Consider the buyer side of a procurement transaction in a life sciences organization. An agent that knows your lab's operational needs, approved vendor list, budget parameters, project timeline, and compliance requirements can monitor inventory, evaluate restocking needs, compare vendor options against your criteria, check compatibility and regulatory status, and place an order without a human in the transaction. The buyer's agent and the seller's systems interact directly. The purchase completes. No sales call required. No demo scheduled. The transaction happens because the buyer's agent found you, evaluated you, and decided you met the criteria.
This has direct implications for how you need to operate on the vendor side. If buyer-side agents are doing the evaluation, they need structured, machine-readable information about your product: pricing, integration requirements, proof points, compliance certifications, compatibility data. Not a PDF brochure. Not a landing page that requires a form fill to see any real detail. Structured data that an agent can ingest, process, and compare. Companies that make themselves agent-discoverable will be in deals that human reps never knew were happening. Companies that require a phone call to get basic information get filtered out before anyone from the buyer side reaches out.
The sales bifurcation is already starting. Transactional information exchange is getting compressed. If a buyer's agent can find your pricing, compare your specs to three competitors, and check your references before your SDR even knows the company was looking, the portion of the sales cycle that was previously a rep walking someone through discovery is gone. What remains valuable is complex multi-stakeholder navigation across organizations where relationships and trust are the currency. Organizational intelligence that no agent has because it's not written down anywhere. The rep who knows the history between two stakeholders at an account, understands who has real influence versus formal authority, and can navigate that complexity over a long cycle. That's not automatable. The reps who thrive in this environment are the ones who understand how to work alongside agents, set goals for them, evaluate their outputs, and focus their own time on the things that genuinely require a human.
What to do now
- Focus on near-term capabilities that already create leverage: monitoring, routing, drafting, enrichment, prioritization, and structured execution.
- Make your product, proof points, and positioning more machine-readable now.
- When models improve, swap them out and you get an instant upgrade
16 How to actually start
Pick one specific, repeatable task. Not "improve our marketing." One workflow: account research briefs before sales calls, or competitive monitoring, or CRM enrichment. Build an agent that does that task. Run it. Watch it. Learn from what works and what doesn't. Then pick the next one.
The knowledge base is the first build, and most people skip it because it feels like documentation work rather than real progress. It is the most important thing you will build. Before you run any execution workflow, document your operating truth: your ICP with specificity, your positioning and what you're competing against and how, your product detail and proof points, your buyer personas and the objections they raise, your voice and the content standards you hold. Start with the messy 20% that contains the most important context. You can add structure later. A working knowledge base with rough edges beats a perfect outline that doesn't exist yet.
Connect it to real data as soon as you can. An agent working with actual CRM records, real analytics data, and live signal feeds is exponentially more useful than one reasoning about hypothetical scenarios. The difference between an agent told "your target accounts are mid-size CROs" and an agent with access to a database of 400 real accounts with enrichment data, deal history, and recent signals is not a marginal improvement. It's a different class of output entirely.
What you'll learn by building cannot be learned by reading about it. You'll learn how agents actually reason and where that reasoning breaks down. You'll learn what instructions produce reliable outputs versus what instructions produce creative but erratic ones. You'll learn where human oversight is genuinely necessary versus where it's just habit. You'll encounter failure modes in a controlled environment before they reach production. That learning is worth more than any vendor demo or conference presentation.
Co-work tools are a valid middle ground if you haven't built the always-on infrastructure yet. They're worth the investment only when you have the knowledge base loaded and real integrations connected. Without those, co-work is an expensive chat with a better interface. With them, it approximates always-on agents with more human touchpoints at each stage. If you're early, start there. Just don't stay there.
One thing is not ambiguous: continuing to use basic chat tools as your primary AI surface is not a strategy. It's using a productivity tool while your competitors build systems. The gap between a team with a working agentic commercial stack and a team using AI as a faster search engine is opening now. Build the thing. Learn by running it. Iterate on what you learn. The teams that start building in 2025 will have two years of institutional memory and system maturity by the time the rest of the field catches up on tooling alone.
What to do now
- Pick one workflow.
- Build the minimum useful knowledge base behind it.
- Connect it to real systems.
- Run it on a small sample with human review.
- Improve it, then add the next workflow.
17 Why this matters right now
We are at an inflection point that commercial leaders in life sciences don't have the luxury of waiting out.
The rate of change in this space is not decelerating. The models are better every month. The agent infrastructure is maturing faster than most internal technology roadmaps move. What you build today on current architecture will run better in 12 months without a full rebuild. The compounding starts now.
The advantage belongs to the builders. If you build the data infrastructure, load the knowledge base, establish the governance structure, and develop the organizational habits for working with agents now, you will have a two-year head start when the rest of your competitive landscape wakes up to what's possible. Your agents will have two years of call transcripts. Two years of content performance data. Two years of objection patterns from real deals. Two years of what-worked and what-didn't embedded in the system. You can't shortcut that.
The people who excel in this next phase are not necessarily the most technical people in your organization. They're the people who get good at working with agents: setting clear goals, evaluating outputs critically, designing feedback loops, and knowing when to override. Those skills are learnable. They're being developed right now by people who started building. Those people are going to be among the most valuable in their organizations. They get hired for the roles that matter. They get promoted because they can run commercial operations at a scale others can't. They make more money because the output they produce is measurable and significant.
The efficiency gap between an agent-enabled commercial operation and a manual one will be impossible to ignore in three to five years. Not because anyone is getting fired and replaced by agents. Because the agent-enabled team produces five times the pipeline with the same headcount. Because their reps walk into every call prepared. Because their content pipeline never stops. Because their competitive intelligence never goes stale. Because their CRM is always current. The manual operation can't match the output.
You don't need to be an engineer to do this. I am not an engineer. I’m a curious tinkerer with domain expertise that over the last 2 years have worked with agents all day every day so I know what works and what doesn’t. I am the example of what a non-technical person can build.
Everything you need to learn is documented online by people who built it and wrote about it. The agents will help you learn to use them. You can ask an agent how to build an agent and get a step by step process of exactly what to do.
You could probably just copy and paste this whole article into a Claude chat, save it to a project, and just start asking it questions of where you should start building. Then tell it to give you a step-by-step guide and check off sections as they are completed.
What you have to do is start. Pick the task. Build the thing. Run it. Look at what it produces. Improve the instructions. Run it again. That's the loop. It's not complicated. The barrier isn't technical complexity. The barrier is starting.
Today is the worst these models will ever be. What you can build right now is already remarkable. What it will be in two years, on the same architecture, is more than most people are willing to predict publicly.
Start now.
18 APPENDICES
Appendix A: Minimum Viable Agentic Stack
A reference architecture for organizations at Level B or C in their maturity. What to build, in what order, without vendor names.
1. Knowledge base: document operating truth first.
Start with your ICP: specific company profiles, titles, firmographic filters, and disqualifying criteria. Add your positioning: what you do, who it's for, what you're competing against, and why buyers choose you over alternatives. Add product detail: features, proof points, technical specifications, integration requirements, compliance certifications. Add buyer personas: the specific objections each role raises and the handling that's worked. Add voice and content standards. Save everything in a structured, searchable format your agent can retrieve from. Do not build any execution workflow before this layer exists. Every workflow that runs without a knowledge base behind it produces outputs you'll spend more time fixing than the workflow saved.
2. Connectivity: connect CRM and analytics before anything else.
Your CRM is the record of commercial truth. Your analytics platform is the record of what's working. Connect both before adding other sources. Once those are live, add call recording transcripts. Those three data sources, connected to your knowledge base, are sufficient to run the highest-value workflows in Section 7. Expand connectivity from there: intent data, social listening, enrichment providers, event platforms. Build in order of signal quality and workflow impact.
3. First execution workflow: pick a high-repetition, low-stakes task.
The criteria for your first workflow: it happens at least weekly, it currently takes someone 30 to 60 minutes of manual work, the output quality is verifiable, and the downside of an imperfect first output is low. CRM enrichment and account research briefs both meet these criteria. Build the workflow, run it, review the first ten outputs manually, adjust the instructions based on what's off, run it again. Your goal in the first workflow isn't perfection. It's learning how the system behaves with your data and your instructions.
4. Observability: build logging before you scale.
Before you add your second or third workflow, add logging. Every agent action should produce a record: what it was asked to do, what it did, what the output was, what the outcome was. Set up a simple dashboard that shows workflow runs, output quality ratings from your reviewers, and cost per run. This infrastructure feels like overhead when you have one workflow. When you have ten, it's how you know what's working and what isn't without reviewing every output manually.
Appendix B: Maturity Self-Assessment
Answer each question honestly. Scoring guidance follows.
- For 1-5 scale questions (Questions 1, 3, 4, 6, 9): use your rating directly.
- For Yes/No/Partial questions (Questions 2, 5, 7, 8, 10): No = 1, Partial = 3, Yes = 5.
- Question 6 is conditional: if you answered No to Question 5, score Question 6 as 1.
Appendix C: Metrics Scorecard
CAC trend vs. agent investment Measure: customer acquisition cost month-over-month, tracked against agent infrastructure spend. Frequency: monthly. What working looks like: CAC is flat or declining as pipeline volume increases. The cost of adding new pipeline is falling even as total pipeline grows.
Conversion rate by channel before and after Measure: lead-to-meeting, meeting-to-opportunity, and opportunity-to-close rates by channel, with a clear before/after baseline from your pre-agent period. Frequency: monthly, with quarterly cohort review. What working looks like: conversion rates improve in channels where agents are active in the workflow. Speed-to-lead improvements show up in inbound conversion within the first 60 days.
Time-in-stage reduction by deal size Measure: average days per pipeline stage, segmented by deal size. Frequency: quarterly. What working looks like: deals move faster through stages where agent-assisted research and follow-up are active. Specifically, stages that rely on rep preparation and follow-through should shorten measurably.
Pipeline created per headcount Measure: total pipeline value generated divided by commercial headcount (sales plus marketing). Frequency: quarterly. What working looks like: this number increases over time as agents handle volume work and your headcount focuses on higher-value activities. Benchmark your pre-agent baseline carefully. This is your long-term proof metric.
Cost per qualified meeting Measure: total cost of outbound activity (agent costs plus human time at fully loaded rate) divided by qualified meetings booked. Frequency: monthly. What working looks like: cost per qualified meeting declines as agents handle more of the research and personalization work that previously required human hours.
Forecast accuracy trend Measure: the percentage of deals that closed as predicted in the 60-day forecast, tracked over time. Frequency: quarterly, reviewed against a pre-agent baseline. What working looks like: forecast accuracy improves as agent risk detection flags at-risk deals earlier, giving your team more time to intervene. A 10 to 15 percentage point improvement in forecast accuracy within 12 months of deploying signal monitoring is a reasonable benchmark.
Appendix D: Agent Security Checklist
Eight controls for commercial leaders. No security engineering background required.
1. Apply least privilege to every agent. Each agent should have access only to the specific systems and data it needs for its defined task. Your competitive intelligence agent does not need CRM write access. Your CRM enrichment agent does not need access to your call recording platform. Define access at setup. Review it quarterly.
2. Validate all untrusted inputs before they reach agent reasoning. Any agent that reads content from external sources (competitor websites, prospect emails, form submissions, third-party data feeds) should have input validation in place that strips or flags content that looks like instructions. Do not pass raw external content directly into agent context without a sanitization step.
3. Require human approval for all irreversible actions. Sending an email to a prospect is irreversible. Updating a contract record is irreversible. Deleting a CRM entry is irreversible. Any agent action that cannot be undone should require explicit human approval in your workflow design. Build this gate before the workflow goes live, not after something goes wrong.
4. Validate agent outputs before they reach external systems. Before an agent-drafted message sends, before an agent-generated content piece publishes, before an agent-recommended change implements, run an output validation step. This can be automated for format and compliance checks. It should include human review for anything customer-facing or public.
5. Log every agent action with a full audit trail. Every task an agent performs should generate a log entry: what it was asked to do, what data it accessed, what it produced, and what the output was routed to. Logs should be retained according to your data retention policy and accessible for review without special engineering support.
6. Rotate credentials and review permissions on a schedule. Agent access credentials should be treated like any other privileged credential: rotated regularly, reviewed when team members change, and revoked immediately when a workflow is deprecated. Set a quarterly calendar reminder for this review.
7. Test for prompt injection in any workflow reading external content. Before a workflow that reads external content goes to production, test it deliberately with inputs designed to manipulate agent behavior. Include a competitor website page that contains hidden instructions. Include an email with text designed to redirect agent actions. Document what the agent does. Fix what breaks.
8. Document your human oversight model and make it auditable. For each production workflow, document: what decisions the agent makes autonomously, what decisions require human review, who is responsible for that review, and where the approval record is stored. This documentation is your compliance foundation for EU AI Act transparency requirements and your defense in any future regulatory inquiry.